Partitioner.Create(1,10,4).GetDynamicPartitions() 为长度为10的序列创建分区,每个分区至多4个元素,分区方法及结果:Partitioner.Create(0, 10, 4).GetDynamicPartitions() 得到3个前闭后开区间:[0, 4)即{0,...
”Partitioner的简单使用“ 的搜索结果
一个使用 node + javascript 的简单分布式 map reduce 系统。 它可以工作(至少在本地主机上),但请注意 - 它真的很慢。 目前仅支持将字符串作为映射值传输,并减少备忘录。 要运行的局部环境(1和控制装置; 2个...
理解数据分区和Partitioner 数据分区(Data Partitioning)是指将大量数据拆分为多个较小的数据块,然后将这些数据块分配给不同的计算资源进行处理。在大数据处理中,数据分区是非常重要的一环,它能够提高系统的...
自定义Partitioner分区
标签: 大数据
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、...
大数据开发技术.pdf
标签: 文档资料
FC 也有 选择谁作为 ActiveNN 的权利,因为最多只有两个节点,目前选择策略 还比较简单(先到先得,轮换)7.JournalNode 高可用情况下存放 namenode 的 editlog 文件. 在 CentOS 环境下,按照伪分布方式安装和配置 ...
Partitioner 组件可以对 MapTask后的数据按Key进行分区,从而将不同分区的Key交由不同的Reduce处理。这个也是我们经常会用到的功能。 1.使用场景 比如上个案例中我们统计出来了每个用户的流量数据,那么我们...
理解Partitioner组件 ## 1.1 什么是Partitioner组件 在MapReduce程序中,Partitioner组件是用来将Mapper的输出按照Key进行分区的组件。它决定了某个Key会被分配到哪个Reducer中去处理。 ## 1.2 Partitioner组件...
} }

Partitioner的作用: 对map端输出的数据key作一个散列,使数据能够均匀分布在各个reduce上进行后续操作,避免产生热点区。 为什么要创建分区? 我们如果文件很大,我们只使用一个reducer,这个reducer就要负责去...
partitioner 是map中的数据映射到不同的reduce时的根据。一般情况下,partitioner会根据数据的key来把数据平均分配给不同的reduce,同时保证相同的key分发到同一个reduce。但当一个数据不平衡时,即某个key对应的...
在hadoop Mapreduce优化...可以提高MapReduce的运行效率,下面就来谈谈这两种技术及其简单的使用。 1 Combiner技术 Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一...
制定这个规则的就是Partitioner。这个过程成为shuffling。 现在要实现这个结构中,把相同FromNode的城市对放入一个Reducer。 Hadoop实战这本书是旧的API写的,用的mapre包内的Partitioner,这里用新API进行了重写。 ...
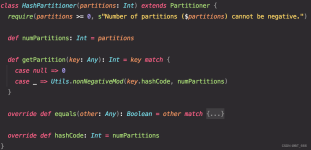
Spark的分区器(Partitioner) HashPartitioner(默认的分区器) HashPartitioner分区原理是对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则余数+分区的个数,最后返回的值就是这个key...
Counter计数器的使用
今天散仙要说的这个分区函数Partitioner,也是一样如此,下面我们先来看下Partitioner的作用: 对map端输出的数据key作一个散列,使数据能够均匀分布在各个reduce上进行后续操作,避免产生热点区。 Hadoop默认...
简单来说,sinks.partitioner决定了数据流将如何分布到下游算子中的不同节点和任务中。 在Flink中,一个任务通常会被分成多个子任务并在不同的节点上并行执行。如果把所有的数据都直接发送给同一个节点,可能会导致...
Partitioner编程
标签: 编程
partitioner编程 目的: 针对上篇博客中输出的结果放在不同的分区中 为什么要用分区? 可以按照不同的属性分别存放,统计比较方便。 例如:统计全国各个市的短信和电话使用情况,考虑到全国各地的人经常会出差,...
Hadoop提供的Partitioner组件可以让Map对Key进行分区,从而可以根据不同key来分发到不同的reduce中去处理,我们可以自定义key的分发规则,如数据文件包含不同的省份,而输出的要求是每个省份对应一个文件。...
MR 之Partitioner分区首先看一段Partitioner的源代码进行分析:/** * Partitions the key space. * * <p><code>Partitioner</code> controls the partitioning of ...
众所周知,Hadoop框架使用Mapper将数据处理成一个个的key/value键值对,在网络节点间对其进行整理(shuffle),然后使用Reducer处理数据并进行最终输出。这其中假如我们有10亿个数据,Mapper会生成10亿个键值对在...
通过前面的学习我们知道...哪个key到哪个Reducer的分配过程,是由Partitioner规定的。在一些集群应用中,例如分布式缓存集群中,缓存的数据大多都是靠哈希函数来进行数据的均匀分布的,在Hadoop中也不例外。 ...
如何使用Hadoop的Partitioner Hadoop里面的MapReduce编程模型,非常灵活,大部分环节我们都可以重写它的API,来灵活定制我们自己的一些特殊需求。 今天散仙要说的这个分区函数Partitioner,也是一样如此,下面...

文章目录一、cat表数据准备1、cat实体类2、数据库表cat和数据3、application.properties配置文件二、分区catPartitionerJob配置1、分区reader2、分区writer3、分区processor4、CatPartitioner分区5、job配置 ...
推荐文章
- 【UBUNTU】ubuntu18.04安装及更新_ubuntu18更新-程序员宅基地
- OpenSSL心脏滴血漏洞(CVE-2014-0160)_openssl漏洞的原因是-程序员宅基地
- 数据结构实验-哈夫曼编码_待编码数据-程序员宅基地
- dataframe的索引遍历_pandas | 如何在DataFrame中通过索引高效获取数据?-程序员宅基地
- 位置传感器_lbk位置传感器-程序员宅基地
- dubbo 报错:java.lang.NoClassDefFoundError: org/I0Itec/zkclient/exception/ZkNoNodeException_dubbo nested exception is java.lang.noclassdeffoun-程序员宅基地
- Spring Boot 2.x 整合 ShardingSphere 5.0.0 实现分库分表_整合shardingsphere-jdbc-core-spring-boot-starter-程序员宅基地
- 表白编码C语言,C语言告白代码,一闪一闪亮晶晶~-程序员宅基地
- mycat_wrapper-linux-aarch64-64-程序员宅基地
- 支持向量机的核函数选择:影响性能的关键因素-程序员宅基地