可伸缩并行化的最简单的形式就是能够互不干涉地同时运行的迭代的循环。本节将会说明如何将简单的循环并行化。 定义 Intel Threading Building Blocks(Intel TBB) 组件的命名空间是 tbb 。简洁起见,只在第一次提到...
”Partitioner的简单使用“ 的搜索结果
一、KafkaOffsetMonitor简述KafkaOffsetMonitor是Kafka的一款客户端消费监控工具,用来实时监控Kafka服务的Consumer以及它们所在的Partition中的Offset,我们可以浏览当前的消费者组,并且每个Topic的所有Partition...
一、键值对RDD数据分区器键值对RDD数据分区器Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个...
董亭亭 快手 实时计算引擎团队负责人 董亭亭,快手大数据架构实时计算引擎团队负责人。目前负责Flink引擎在快手内的研发、应用...第二部分会重点介绍在生产环境中经常使用的 kafka connector 的基本的原理以及使用方
Spark分区器HashPartitioner和RangePartitioner代码详解 总览图
map/reduce之间的shuffle,partition,combiner过程的详解 Shuffle的本意是洗牌、混乱的意思,类似于java中的Collections.shuffle(List)方法,它会随机地打乱参数list里的元素顺序。MapReduce中的Shuffle过程。...
Hadoop支持多种语言开发MapReduce程序,但是对JAVA语言的支持最好。编写一个MapReduce程序需要新建三个类:Mapper类、Reduce类、驱动类。Mapper类何Reduce类也可以作为内部类放在程序执行主类中。
一、KafkaOffsetMonitor简述 KafkaOffsetMonitor是Kafka的一款客户端消费监控工具,用来实时监控Kafka服务的Consumer以及它们所在的Partition中的Offset,我们可以浏览当前的消费者组,并且每个Topic的所有...
1. Hadoop包含两核心部分 hdfs Hadoop distribute file system -- hadoop分布式文件系统,存储数据 Namenode、Datanode 常用命令形式:hadoop fs -ls / hadoop fs -mkdir MapReduce ...
19年下半年,随着互联网、移动互联网的飞速发展,信息化时代到来。无论是在传统行业还是在新兴的创新型企业中,都开始面临海量数据的存储、处理、分析、挖掘等方面的挑战。尤其是当下中国,近几年信息技术革命带来的...
一、RDD的Join操作有哪些? (一)Join:Join类似于SQL的inner join操作,返回结果是前面和后面集合中配对成功的,过滤掉关联不上的。源代码如下: /** Return an RDD containing all pairs of elements with ...
Transformation处理的数据为Key-Value形式的算子大致可以分为:输入分区与输出分区一对一、聚集、连接操作。 输入分区与输出分区一对一 mapValues mapValues:针对(Key,Value)型数据中的Value进行Map操作,而...
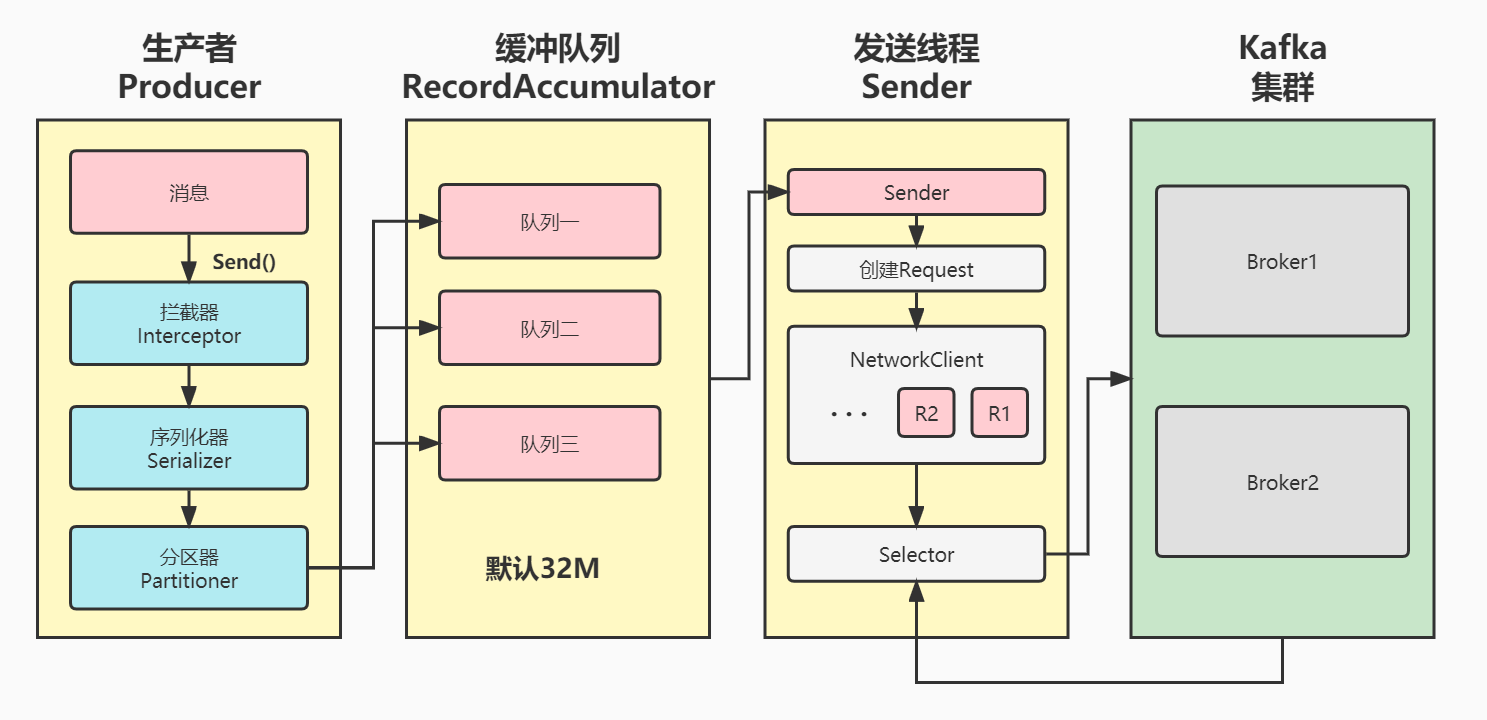
通过...producer比consumer要简单一些。一、旧版本producer0.9.0.0版本以前,是由scala编写的旧版本producer。入口类:kafka.producer.Producer代码示例:Properties properties = new...
例如在 SQL client JAR 中,Kafka client 依赖被重置在了 org.apache.flink.kafka.shaded.org.apache.kafka 路径下...由于 Kafka 消息中消息键是可选的,以下语句将使用消息体格式读取和写入消息,但不使用消息键格式。
在系统升级或迁移时,用户常常需要将一个 Kafka 集群中的数据导出(备份),然后在新集群或另一个集群中再将数据导入(还原)。通常,Kafka集群间的数据复制和同步多采用 Kafka MirrorMaker,但是,在某些场景中,受...
函数tf.variable_scope的简单介绍 经常看到这个函数,所以特地查了一下源码单独记一下。 参考资料: $PYTHONHOME/lib/python3.5/site-packages/tensorflow/python/ops/variable_scope.py ...

Apache Sedona(发音"sē-nō")是一款开源的分布式分析引擎,它提供基于 Apache Spark 的空间索引能力,可对空间数据进行高效查询、聚合与分析。性能优异:Apache Sedona采用了光栅化技术将矢量数据转换成栅格形式...
一、RDD 编程 二、累加器 三、广播变量

Flink 是一个以流为核心的高可用、高性能的分布式计算引擎。具备流批一体,高吞吐、低延迟,容错能力,大规模复杂计算等特点,在数据流上提供数据分发、通信等功能。
和transformation(转换)一样,键值对RDD也可以使用基础RDD上的action(开工),并且键值对RDD有一些利用键值对数据特性的的action,如下表: 表4-3 键值对RDD上的action 函数名 描述 例子 结果 countByKey...

tf.variable_scope(): 可以让变量有相同的命名,包括tf.get_variable得到的变量,还有tf.Variable变量 它返回的是一个用于定义创建variable(层)的op的上下文...如何创建新variable的简单示例: with tf.variabl...
1.C++编程中使用librdkafka库去连接kafka集群分为生产...过程很简单不再这里详细说明。 一.生产端使用 在编译完之后会有一个rdkafka_example.cpp,参考他进行编写程序。主要逻辑如下: RdKafka::Conf *m_conf; ...
具体实现bean对象序列化步骤如下。(1)实现Writable接口(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中...
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现各种异构数据源之间高效的数据同步功能。...本文简单介绍如何使用datax同步cassandra的数据,针对几种常见的场景给出配置文件示...

推荐文章
- 梁宁的产品思维30讲--听后感-程序员宅基地
- SpringBoot常见面试题详尽-程序员宅基地
- Excel常用:将文本格式的数值转换为数字等-程序员宅基地
- 拾起王慧文的AI梦,美团冲向“光年之外”?-程序员宅基地
- JSP入门-程序员宅基地
- Windows下Apache Tomcat 8安装配置_tomcat8 windows部署-程序员宅基地
- 关于有限脉冲响应滤波器_满足指标滤波器阶数是多少有限冲激响应-程序员宅基地
- 使用python将excel转为lua文件_# 当前脚本路径 curpath = os.path.dirname(os.path.abspath-程序员宅基地
- LimeSDR实验教程(4) LoRa通信_limesuitegui lora-程序员宅基地
- 计算机网络(超级详细笔记)_计算机网络笔记-程序员宅基地