”SPARK“ 的搜索结果
spark
标签: JupyterNotebook
适用于Python的课程笔记本和适用于大数据的Spark 课程幻灯片:Python和大数据的火花 Spark DataFrames Spark DataFrames部分介绍 Spark DataFrame基础 Spark DataFrame操作 分组和汇总功能 缺失数据 日期和时间戳 ...
Hive 是将 SQL 转为 MapReduce。SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行在学习Spark SQL前,需要了解数据分类。

sparkcore sparksql sparkstreaming structedstreming
【代码】Spark SQL编程初级实践。
Spark基础 为什么选择Spark? Spark基础配置 Spark WordCount实例 Spark运行架构 Spark分区 Spark算子 Spark优化
Spark On YARN模式的搭建比较简单,仅需要在YARN集群上的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。2)Spark中引入的RDD是分布在多个计算节点上的只读对象集合,这些集合是弹性的...

部署Spark集群大体上分为两种模式:单机模式与集群模式大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。
目录一、Spark概述(1)概述(2)Spark整体架构(3)Spark特性(4)Spark与MR(5)Spark Streaming与Storm(6)Spark SQL与Hive二、Spark基本原理(1)Spark Core(2)Spark SQL(3)Spark Streaming(4)Spark基本...
而我们之前采用的PostgreSQL驱动的方式就是因为使用了JDBC,导致写入速度非常慢。综合官网提供的这3中方式,我们最终选择了Greenplum-Spark Connector这种方式,但是只提供了Spark2.3版本支持,其他版本未验证过。。
在 DAG 中又进行 Stage 的划分,划分的依据...Spark 的 Job 来源于用户执行 action 操作(这是 Spark 中实际意义的 Job),就是从 RDD 中获取结果的操作,而不是将一个 RDD 转换成另一个 RDD 的 transformation 操作。
首先来聊聊什么是Spark?为什么现在那么多人都用Spark? Spark简介: Spark是一种通用的大数据计算框架,是基于**RDD(弹性分布式数据集)**的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以...
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
Spark系列之Spark启动与基础使用
使用命令/software/spark-3.4.0-bin-hadoop3/bin/spark-submit --class “hdfstest” /software/hdfstest/target/scala-2.12/a-simple-hdfs-test_2.12-1.0.jar >& 1 |grep The 运行jar包运行成功。
(2)复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容。(3)复制slaves.template成slaves (配置worker节点)讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**4、Scala安装...

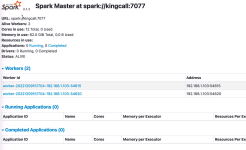
按回车键提交Spark作业后,观察Spark集群管理界面,其中“Running Applications”列表表示当前Spark集群正在计算的作业,执行几秒后,刷新界面,在Completed Applications表单下,可以看到当前应用执行完毕,返回...
编译输出的Spark Hudi依赖位于hudi/packaging/hudi-spark-bundle/target,将其中的hudi-spark3.x-bundle_2.12-0.xx.x.jar复制走备用。或者是在spark-defaults.conf中增加spark.hadoop.yarn.timeline-service.enabled...
今天要实现的内容是如何将昨天的HelloDetlaLake 在spark集群上运行,。里面的解决方法就是把Delta lake相关的jar包复制到spark安装目录下面的jar目录里面,于是决定尝试一下。复制完后,记得重新运行第2和第3步,...

基于Hadoop+Spark招聘推荐可视化系统的设计与实现(论文+源码)_kaic.zip
大数据集群之spark2(2)
标签: 大数据
一、环境准备。
在IDEA中运行spark程序

Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
推荐文章
- GPT-ArcGIS数据处理、空间分析、可视化及多案例综合应用
- 在Debian 10上安装MySQL_debian mysql安装-程序员宅基地
- edge 此项内容已下载并添加到 Chrome 中。_一个小扩展,解决Chrome长期以来的大痛点...-程序员宅基地
- vue js 点击按钮为当前获得焦点的输入框输入值_vue获得当前获得焦点的元素-程序员宅基地
- Android 资源文件中@、@android:type、@*、?、@+含义和区别_@android @*android-程序员宅基地
- python中的正则表达式是干嘛的_Python中正则表达式介绍-程序员宅基地
- GeoGeo多线程_geo 多线程-程序员宅基地
- phpstudy的Apache无法启动_phpstudy apache无-程序员宅基地
- 数据泵导出出现ORA-31617错误-程序员宅基地
- java基础巩固-宇宙第一AiYWM:为了维持生计,两年多实验室项目经验之分层总结和其他后端开发好的习惯~整起_java两年经验项目-程序员宅基地