
”Spark工作原理“ 的搜索结果
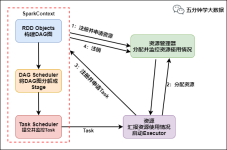
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。 1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等) 2、...

文章目录前言一、Spark运行1.1核心组件1.2运行流程1.3集群部署模式1.4yarn模式运行机制1.5Spark RPC框架二、SparkContext2.1...原理四、shuffle详解4.1Spark Shuffle的两个阶段4.2Spark Shuffle技术演进4.3Hash Shuffle...


最近在学习spark,把自己的一些理解写下来。 希望与大家一同交流。 一、Spark 介绍及生态 Spark是UC Berkeley AMP Lab开源的通用分布式并行计算框架,目前已成为Apache软件基金会的顶级开源项目。至于为什么我们...
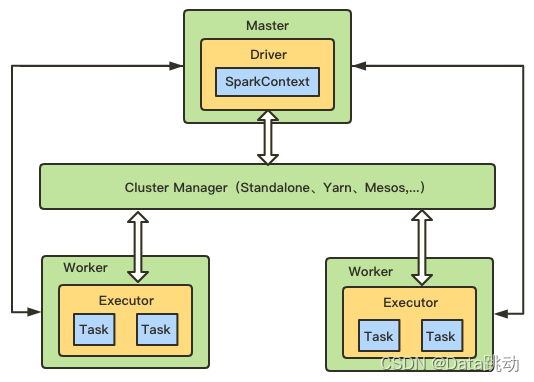
下面我们来分析一下Spark的工作原理 来看这个图 首先看中间是一个Spark集群,可以理解为是Spark的 standalone集群,集群中有6个节点 左边是Spark的客户端节点,这个节点主要负责向Spark集群提交任务,假设在这里...
整理网络上关于spark的资料,对于spark1.0 架构设计,执行细节进行详细描述,非常适合于了解基本spark之后继续学习spark人员做深入了解
一、Spark 是什么 Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用分布式并行计算框架。Spark拥有Hadoop MapReduce所具有的优点,但和MapReduce 的最大不同之处在于Spark是基于内存的迭代式计算——...

Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。 1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等) 2、...
华为教程,内容由浅入深,适合各个层次学习,欢迎大家讨论
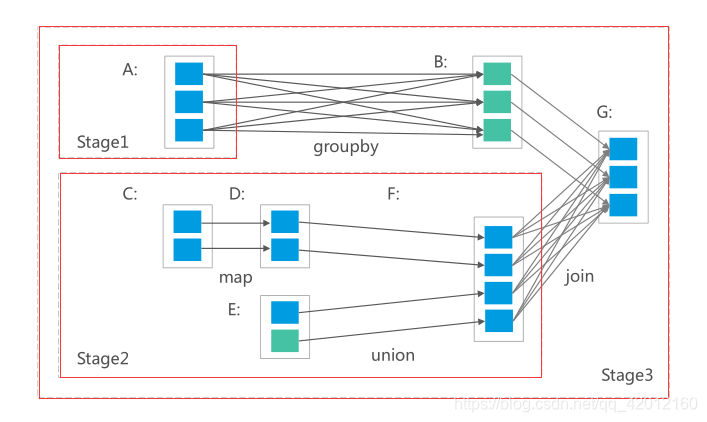
spark shuffle原理, 总结,包括map, reduce的原理等
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis以及TCPsockets,从数据源获取数据之后,...
文章主要通过八个方面全面介绍了spark的架构原理,更多内容请看全文。ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的...
Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。...
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。 1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等) 2、...
Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如何处理代码分布式执行问题的资料少之又少,这也是我撰写文本的目的。Spark运行在...
spark内部原理介绍
标签: spark
基于RDD的架构,在这个开源系统栈里包括作为公共组件的Apache Spark;处理SQL的Shark;和处理分布式流的Spark...我们的实现为传统和新的数据分析工作提供了很好的性能,并成为第一个使得用户可以组合这些计算任务的平台。
Spark核心技术原理透视一Spark运行原理.pdf

介绍了spark的技术原理、特征、rdd计算模型、任务调度原理等核心内容
spark基本工作原理
标签: spark工作原理
spark基本工作原理 spark基本原理是怎么样?包括哪些内容? 1、分布式 2、主要基于内存(一部分读取磁盘) 3、迭代式计算 下面用图来表示:
推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地