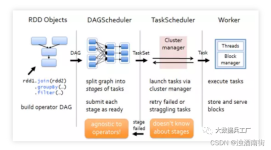
DAGSchduler对stage的划分,从出发action操作开始,往前倒推。首先会为最后一个rdd创建一个stage,往前倒推的过程中如果rdd之间存在宽依赖又创建一个新的stage,之前的最后一个rdd就是最新的stage的最后一个rdd ,...
”dagschduler“ 的搜索结果
当前,Spark 有3种不同类型的 shuffle 实现。每种实现方式都有他们自己的优缺点。在我们理解 Spark shuffle 之前,需要先熟悉 Spark 的 execution model 和一些基础概念,如:MapReduce、逻辑计划、物理计划、RDD、...
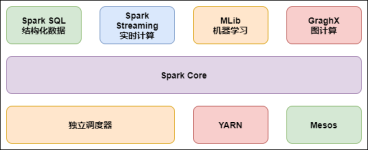
Spark学习01之基础知识篇
标签: spark
文章目录1. RDD(Resilient Distributed Dataset)弹性分布式数据集1.1 创建RDD1.2 持久化2. 提交任务2.1 Standalone-client模式提交任务2.2 Standalone-cluster模式提交任务2.3 Yarn-client模式提交任务2.4 Yarn-...


spark CTAS nuion all (union all的个数很多)导致超过spark.driver.maxResultSize配置(2G)
DAGScheduler DAGScheduler是Spark中比较重要的类,实现了面向DAG的高层次调度,DAGScheduler通过计算将DAG中的一系列RDD划分到不同的Stage,然后构建这些Stage之间的父子关系,最后将每个Stage按照Partition切分为...
本人此次的DAGScheduler 源码剖析将涉及最底层的数据结构,每个细节的实现原理,算法,优化细节,各个组件之间交互动作以及纠正网上的一些错误介绍等....保证国内最新最全最细的源码剖析!
目录TaskScheduler调度算法与调度池TaskScheduler任务提交与资源分配提交Task资源分配 TaskScheduler调度算法与调度池 在DAGScheduer对Stage划分,DAGScheduer将Task提交给TaskScheduler,将多个Task打包为...
在spark源码分析之stage生成中,我们讲到Spark在DAGSchduler阶段会将一个Job划分为多个Stage,在上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,...
DAGSchduler主要创建job, 根据宽窄依赖切分stage, 提交stage个TaskScheduler 一、DAGScheduler的创建 在SparkContext中创建 @volatile private var _dagScheduler: DAGScheduler = _ //getter setter private...
概述 spark主程序中当遇到action算子的时候,就会提交一个job。一个job通常包含一个或多个stage,各个Stage之间存在着依赖关系,下游的Stage依赖于上游的Stage,Stage划分过程是从最后一个Stage开始往前执行的,...
背景介绍 当正在悠闲敲着代码的时候,业务方兄弟反馈接收到大量线上运行的spark streaming任务的告警短信,查看应用的web页面信息,发现spark应用已经退出了,第一时间拉起线上的应用,再慢慢的定位故障原因。...
spark事件总线的核心是LiveListenerBus,其内部维护了多个AsyncEventQueue队列用于存储和分发SparkListenerEvent事件。 spark事件总线整体思想是生产消费者模式,消息事件实现了先进先出和异步投递,同时将事件的...
Spark的Action算子会触发job的执行,job执行流程中的数据依赖关系是以Stage为单位的,同一Job里的Stage可以并行,但是一般如果有依赖则是串行。所有Action算子都会执行SparkContext的RunJob-》DagScheduler的Runjob-...
Spark DAGScheduler 源码解析 问题描述 对与Spark执行原理有一定了解的同学对于DAG图(有向无环图,Directed Acyclic Graph的缩写)都会有一定的了解,它描述了RDD之间的依赖关系,和RDD的很多特性都有一定联系。...
Spark中对RDD的操作大体上可以分为transformation级别的操作和action级别的操作,transformation是lazy级别的操作,action操作(count、collect等)会触发具体job的执行,而每个job又会被划分成一个或者多个Stage,...
大家应该知道,我们对作业进行运行时,是通过action算子来实现job的划分,而每个job在提交过程中,又是怎样去处理的呢,今天我给大家介绍一下spark2.x的源码。 先通过action算子,调用run job()方法,例如foreach...
主要内容: DAGScheduler的官方注释 DAGScheduler的创建 Job的提交处理与Stage的划分 官方注释 The high-level scheduling layer that implements stage-oriented scheduling....It computes a DAG of stages for ...
1、普通的shuffle过程①假设节点上有2个ShuffleMapTask,节点上有2个cup core②ShuffleMapTask的输出,称为shuffle过程的第一个rdd,即MapPartitionRDD③每个ShuffleMapTask会为每一个task创建一份bucket内存缓存,...
在DAGSchduler.scala中,封装taskset,使用TaskSchduler提交了taskset,下面通过源码解析,TaskSchduler对task分配到executor和本地化级别。TaskSchdulerImpl.scala/** * taskSchduler 提交taskset的入口 */ ...
①SparkContext的运行原理
大数据科学丛书 Spark核心源码分析与开发实战 第4章 Spark的运行模式 1.运行模式概览 standalone模式,即独立模式,通过它可以独立部署Spark集群,比如当我们只需要借助Spark进行大数据计算时,此模式是最佳模式。...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地