hadoop之impala简单使用共8页.pdf.zip
”hadoop之impala简单使“ 的搜索结果
HADOOP 文件系统SHELL; hive批处理、交互式SHELL; IMPALA介绍、支持的命令。
Impala 驱动包 Cloudera_ImpalaJDBC4_2.5.41.zip Cloudera_ImpalaJDBC41_2.5.41.zip Cloudera-JDBC-Driver-for-Impala-Install-Guide.pdf Cloudera-JDBC-Driver-for-Impala-Release-Notes.pdf
Apache Impala impala 是 cloudera 提供的一款高效率的 sql 查询工具,提供实时的查询效果 impala 是基于 hive 并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。 Impala 与 Hive 关系 ...
ambari2.7.5集成HDP3,本身不带impala、kudu 故集成cloudera的impala、kudu安装方式 ambari插件安装方式。 解压放到/var/lib/ambari-server/resources/stacks/HDP/3.1/services/下
1. Impala的基本概念 1.1 什么是Impala Impala就是使用SQL语句来操作Hive中的数据库和表,它可以提供低延迟的交互式的SQL查询功能.它与Hive共用表的元数据信息,所以需要使用Impala必须要先有Hive. 1.2 Impala的优...
标题1.2.3.4. 1. 2. 3. 4.
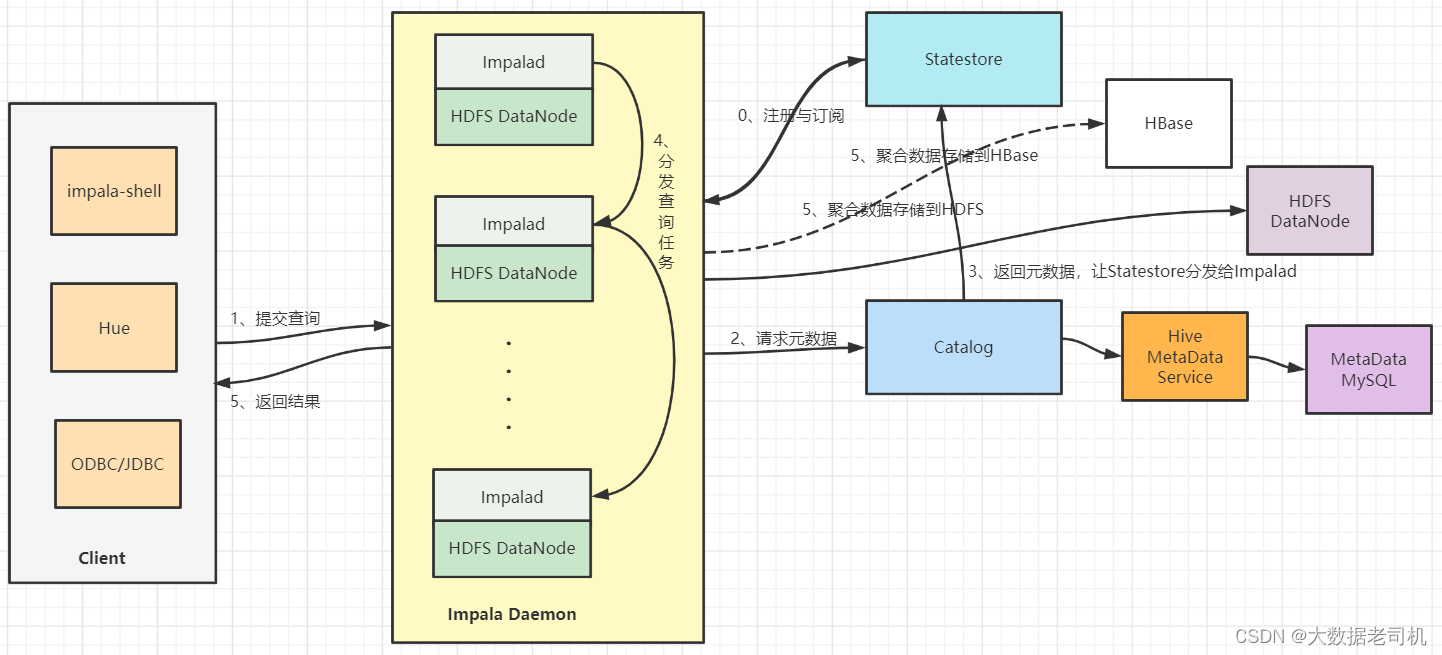
Impala介绍 Impala是实时交互的大数据查询工具 智能的SQL查询 分布式的数据查询 实时的数据查询 Impala体系结构 Impalad:运行于集群中的每一个节点,负责读写文件及处理用户请求 Metastore:负责集群...
impala 是基于hive的大数据实时分析查询引擎,直接使用Hive的元数据库metadata意味着impala元数据都存储在hive的metadstore中并且impala兼容hive的 sql解析,实现了hive得sql语义子集,功能还在不断完善中。 shell...
Centos7原生hadoop环境,搭建Impala集群和负载均衡配置
闪电般的分布式查询,用于存储存储在Apache Hadoop集群中的PB级数据。 Impala是一个现代的,大规模分布,大规模并行的C ++查询引擎,可让您分析,转换和合并来自各种数据源的数据: 同类最佳的性能和可伸缩性。 ...
hadoop impala 随着Hadoop的发展,开发人员获得了具有更多功能的新抽象和发行版本。 Hadoop的新版本和新版本将提供改进的Hadoop,同时消除了早期版本的弊端。 Facebook引入了Apache Hive,以管理和处理存储在...

一、Impala概述 ### --- [交互查询工具Impala] ~~~ [交互查询工具Impala] ~~~ [Impala的优势] ~~~ [Impala的缺点及适用场景] ### --- Impala大纲 ~~~ 第 1 部分 Impala概述(Impala是什么,优势,劣势,与Hive...
一、短路读取配置步骤 ### --- 创建短路读取本地中转站 ~~~ DataNode启动失败有可能是该...[root@linux121 ~]# mkdir -p /var/lib/hadoop-hdfs ### --- 修改hdfs-site.xml [root@linux121 ~]# vim /opt/yan...
Hadoop Impala connect hive2 jdbc related Hadoop Impala connect hive2 jdbc related
1 Hadoop-Impala性能优化系列开幕 1.1 序和简介 1.1.1 序 某集团数据中心业务支撑平台建设也2年了,磕磕碰碰一路走来。最近的hadoop业务大规模急速上升...
基于Hadoop的实时查询 Cloudera Impala ,Cloudera 发布实时查询开源项目 Impala (黑斑羚)!多款产品实测表明,比原来基于Map...
~~~ 使⽤用Yum⽅式安装Impala后,impala-shell可以全局使用; ~~~ 进入impala-shell命令⾏impala-shell进⼊到impala的交互窗⼝ [root@linux123 ~]# impala-shell Starting Impala Shell without...
上个月参与了公司的大数据接口平台项目,其中就使用到了impala提供实时查询接口。而且,在使用当中还遇到了关于impala版本的问题,主要是sql语法上的差异,目前已经到了2.4了,而我们公司集群环境使用的版本是1.3。 ...
1.1 Hadoop-impala十大优化之(6)—控制资源使用最佳实践 有时,平衡原始查询性能对可扩展性需要限制的资源量,如内存或中央处理器,使用一个单一的查询或组查询。Impala可以使用多种机制,有助于消除负荷重的同时...
1.1 Hadoop-impala十大优化之(8)—HDFS缓存最佳实践 1) HDFS缓存的Impala的概述 2) 设置缓存为HDFS的Impala 3) 使用HDFS的Impala表和分区缓存 4) 加载和HDFS启用缓存删除数据 5) HDFS的缓存管理和...
Apache Impala impla是个实时的sql查询工具,类似于hive的操作方式,只不过执行的效率极高,号称当下大数据生态圈中执行效率最高的sql类软件 impala来自于cloudera,后来贡献给了apache impala工作底层执行依赖于...
hadoop-impala十大优化之(7)—Impala查询运行时过滤最佳实践 1.1.1 运行时过滤 runtime_filter_mode=GLOBAL. 运行时过滤是一种广泛的优化在CDH 5.7 / Impala 2.5及更高版本可用特性。只有当表中数据的一小...
文章目录impalaimpala的架构impala的查询计划impala的安装挂载磁盘 impala impala是cloudera 公司开源提供的一个sql交互查询的工具,兼具hive的优势,具有批量处理以及实时处理等优势。 impala的优点与缺点: impala...
一、安装Impala ### --- [交互查询工具Impala] ~~~ [Impala的安装及入门案例-安装步骤] ~~~ [Impala的安装及入门案例-配置详解] 二、集群规划 服务名称 linux121 linux122 linux123 ...
1、运行zookeeper 三集群都运行 $ systemctl stop firewalld.service ...2.启动hadoop # 先进入到文件的根目录 # 启动dfs sbin/start-dfs.sh # 启动yarn sbin/start-yarn.sh # 启动历史记录 sbin/mr-jobhistory-daemo
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地