
”impala“ 的搜索结果
NULL 博文链接:https://shawjerson-gmail-com.iteye.com/blog/2191155
在本文中,我们将介绍如何使用Impala创建各种类型的表。Impala是一个用于大规模数据分析的分布式SQL查询引擎,它支持多种数据类型、文件格式和表属性。通过掌握这些知识,您可以根据需要创建和管理Impala表,以满足...
Golang Apache Impala驱动程序 适用于Go的软件包的Apache Impala驱动程序 据我们所知,这是Apache Impala唯一具有TLS和LDAP支持的纯golang驱动程序。 该驱动程序的当前实现基于Hive Server 2协议。 可以在获得基于...
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
为集群配置Impala和MapreduceJava开发Java经验技巧共6页.pdf.zip
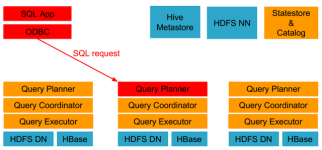
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,impala是参照谷歌的新三篇论文...
hadoop之impala简单使用共8页.pdf.zip
hadoop之impala简单使用共8页.pdf.zip
impala-base64 Impala Base64 UDF实现。Impala Base64 UDF安装将共享库作为/user/pulse/lib/impala/libPulseB64Udf.so复制到HDFS CREATE FUNCTION encode64(STRING) RETURNS STRING LOCATION '/user/pulse/lib/...
今天用JDBC创建kudu表的时候报错: 打印的SQL: CREATE TABLE external_table2 (companyId BIGINT, workId BIGINT, ...这个SQL是没问题的,能到impala-shell当中完美执行。不过JDBC死活不行,疯狂报错
impala部署安装
标签: 大数据
下载地址:https://mirrors.aliyun.com/centos/7/os/x86_64/Packages/重新上传libkudu_client.so.0依赖包。处理方法:下载readhat依赖包。上传玩还是报错,加了权限OK。查看依赖确实没有依赖。
1、通过亿级数据量在hive和impala中查询比较text、orc和parquet性能表现(一) 网址:https://blog.csdn.net/chenwewi520feng/article/details/130465139 本文通过在hdfs中三种不同数据格式文件存储相同数量的数据,...
1、通过亿级数据量在hive和impala中查询比较text、orc和parquet性能表现(二) 网址:https://blog.csdn.net/chenwewi520feng/article/details/130465463 本文通过在hdfs中三种不同数据格式文件存储相同数量的数据,...
Impala是一款基于Hive的大数据分析查询引擎,直接使用Hive的元数据Metastore,因此如果使用Impala需要先安装Hive并启动Metastore服务。Impala不依赖MapReduce而是将执行计划树进行并行计算,使用拉的方式获取结果...
本文不是事故原因汇总,只介绍当Impala集群出现事故时的处理流程,以最大限度保留现场信息,方便事后调查。第一节介绍故障表现和对应的操作建议,第二节介绍每个操作的具体执行流程。本文将不定期更新,欢迎留言反馈...
JDBC-impala驱动包
标签: java
包含 ImpalaJDBC41.jar和ImpalaJDBC42.jar
springboot集成impala,包含yml文件、impala配置Bean、ImpalaJDBC41-2.6.4.1005.jar和impala在pom.xml中的配置,有问题留言
把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。...
目前impala 使用下来有很多的问题 ,但是开源社区并不活跃,阿里云的技术支持也不是很熟悉impala框架,经常有解决不了的问题,只能去深度查询问题,并通过一些定时脚本去解决。 目前doris 开发团体无偿的提供了...
直接pip install impala 是不行滴,按照以下步骤安装就会成功! 一路安装就可以 1、pip install six 2、pip install bit_array 3、pip install thriftpy 4、pip install thrift_sasl 5、pip install impyla 测试: ...
由于impala处理日期的函数如date_sub(),date_trunc(),last_day()等这些日期处理函数还需要进行日期格式化为yyyy-MM-dd使用,sql代码段过长,导致频繁嵌套过于复杂.所以自定义udf函数解决这些问题.以下为实现过程.
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。...
impala-queryimpala查询接口
Impala是一个现代的,大规模分布,大规模并行的C ++查询引擎,可让您分析,转换和合并来自各种数据源的数据: 同类最佳的性能和可伸缩性。 支持存储在 , , , , , 等中的数据! 广泛的分析SQL支持,包括窗口...
因需要将impala仅仅作为数据源使用,而python有较好的数据分析函数,所以需要使用python客户端来获取impala中的表数据,这里的测试环境是: 操作系统:win7 (linux下也可行) python 2.7 大数据环境:centos6.6 CDH...
dbeaver中连接impala所需jdbc包,适用于CDH5.16.2,impala2.12
ImpalaJDBC驱动包,用于Impala数据库连接,Maven配置所需的jar包
从零开始讲解大数据分布式计算的发展及Impala的应用场景,对比Hive、MapReduce、Spark等类似框架讲解内存式计算原理,基于Impala构建高性能交互式SQL分析平台 课程亮点 1,知识体系完备,从小白到大神各阶段读者均...
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地