”pack_padded_seq“ 的搜索结果
019pack_padded_sequence用法与完整示例
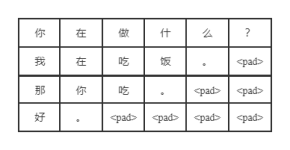
但是填充后虽然长度相同,但是会有很多无效的填充值,会浪费计算资源为了使 RNN 可以高效的读取数据进行训练,就需要在 pad 之后再使用 pack_padded_sequence 对数据进行处理; input:pad后的序列(由大到小排好序...
一、问题背景 在NLP的相关任务中,我们使用RNN或LSTM处理文本序列时,通常来说句子的长度是... 因此,为了解决这样的问题,在将序列送给 RNN 进行处理之前,需要采用 nn.utils.rnn.pack_padded_sequence 进行压
the fact that pe32 isn t padded where pe32+ is 64-bit means union won t work right.
这个函数主要做了两件事: pad 和封装,因为在rnn模型中,一般先将batch中的数据按照一个...需要注意的是,默认条件下,我们必须把输入数据按照序列长度从大到小排列后才能送入 pack_padded_sequence ,否则会报错。.
是 PyTorch 中用于处理变长序列数据的函数。它的主要作用是将一个批次的序列数据打包成适合输入到 RNN(循环神经网络)模型中的形式,以避免对填充部分进行多余的计算。在自然语言处理任务中,例如文本分类、机器...

此文章为阐述pytorch中pack_padded_sequence 和pad_packed_sequence的原理 在变长序列文本中,一个batch中的各样本长度可能不一致,在使用RNN模型时,需要填充至统一长度,被填充的位置实际无意义。我们通常取最后一...

pack_padded_sequence()与pad_packed_sequence()这两个函数属于torch.nn.utils包中用来处理数据的。前者用于压紧数据,后面用于解压数据。 一. 官方+理解 1. pack_padded_sequence '官方函数' torch.nn.utils.rnn....
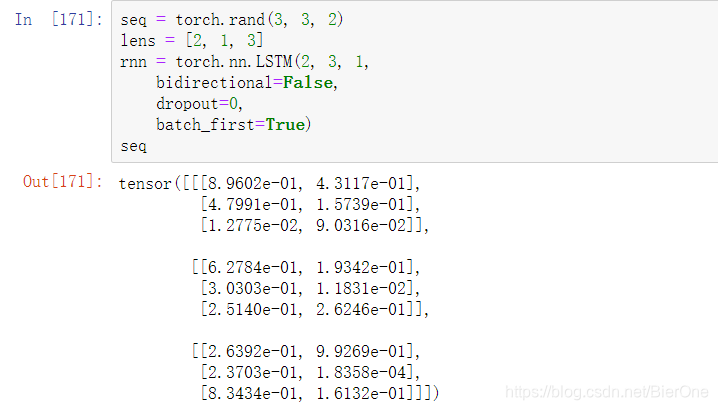
RNN之pack_padded_sequence()和pad_packed_sequence()具体使用代码完整展现
问题 当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding...主要是用函数torch.nn.utils.rnn.pack_padded_sequence()和torch.nn.utils.rnn.pad_packed
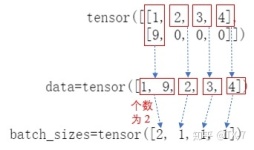
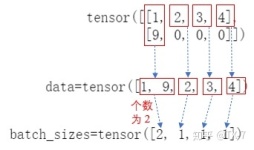
pack_padded_sequence 类似与一个压缩操作。 举个例子: 有一个tensor([[1,2,0], [3,0,0], [4,5,6]]),经过 pack_padded_sequence 之后会得到一个tensor([4,1,3,5,2,6]);再经过pad_packed_sequence之后会得到tensor...
torch.nn.rnn.pack_padded_sequence及pad_packed_sequence的理解pytorch官网解释理解某博主解释 pytorch官网解释理解 torch.nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False, padding_value=0.0, ...
为什么要用pack_padded_sequence 在使用深度学习特别是RNN(LSTM/GRU)进行序列分析时,经常会遇到序列长度不一样的情况,此时就需要对同一个batch中的不同序列使用padding的方式进行序列长度对齐(可以都填充为batch...
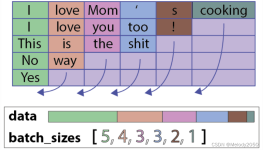
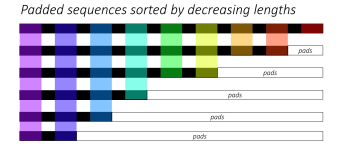
为什么有pad和pack操作? 先看一个例子,这个batch中有5个sample 如果不用pack和pad操作会有一个问题,什么问题呢?比如上图,句子“Yes”只有一个单词,但是padding了多余的pad符号,这样会导致LSTM对它的表示通过...
对一个已打包的序列进行解包,这个打包的序列通常是通过。设置为False,输入序列将无条件地被排序。,序列应该按长度降序排列。函数从一个填充的序列得到的。还是之前的packed。
pad_sequence 填充可变长度张量列表 例子 >>> from torch.nn.utils.rnn import pad_sequence >>> a = torch.ones(25, 300) >>> b = torch.ones(22, 300) ...torch.Size
问题描述:在实现模型的...希望能得到帮助【操作步骤&问题现象】API 欠缺【截图信息】 解答:MindSpore的RNN系列API设计是不做pack和pad的,而是使用seq_length来传入padding前的batch中每条数据的实际长度,来保证p
但pad不能参与到训练,这就给广大的炼丹师带来了麻烦,但幸好Pytorch给我们提供了两个函数pack_padded_sequence与pad_packed_sequence让我们很好的解决了这个问题。 import torch from torch.nn.utils.r
解决RNN训练过程中batch中的文本长短不一问题。


推荐文章
- Java 中应用Dijkstra算法求解最短路径_路由最短路径代码java-程序员宅基地
- Mybatis-plus解决selectOne查询多个会报错的问题_mybatisplus selectone-程序员宅基地
- 【android】android12蓝牙框架_android 蓝牙框架-程序员宅基地
- 玩转X-CTR100 l STM32F4 l PS2无线手柄-4WD智能小车-程序员宅基地
- (深度学习)基于残差卷积——resnet的水稻病害识别_resnet152-程序员宅基地
- Esp8266 进阶之路34 【外设篇③】乐鑫esp8266 NONOS SDK 3.0编程使用 SPI 驱动基于Max7219芯片的八位数码管,显示日期信息。(附带Demo)_8266时钟代码 数码管-程序员宅基地
- 2024年阿里云服务器地域选择方法_地域城市分布表-程序员宅基地
- 【云驻共创】云原生应用架构之企业核心业务未来架构演进路线及华为云方案_基于云原生架构构建核心业务支撑系统应用试点研究-程序员宅基地
- 实验十九、利用运算电路解方程_利用运算电路求解方程的方法研究-程序员宅基地
- Vue3+ElementPlus 根据路由 自动创建二级菜单_vue 项目 element新增菜单下级页面-程序员宅基地