”pad_packed_sequence“ 的搜索结果
对一个已打包的序列进行解包,这个打包的序列通常是通过。设置为False,输入序列将无条件地被排序。,序列应该按长度降序排列。函数从一个填充的序列得到的。还是之前的packed。
主要是用函数torch.nn.utils.rnn.PackedSequence()和torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来进行的,分别来看看这三个函数的用法。 1、torch.nn.utils.rnn....
使用的主要好处是。因为通过跳过填充部分,RNN不需要在这些部分进行无用的计算。这特别对于处理长度差异很大的批量序列时很有帮助。
-nopad do not pad filesystem to a multiple of 4K -check_data add checkdata for greater filesystem checks -root-owned alternative name for -all-root -noInodeCompression alternative name for -noI -...
PAD >(0)来补全至相同长度的序列。虽然这个时候序列的长度是一致的,但是序列中填充了许多无效值 0 ,这个时候喂给 RNN 进行 forward 计算,不仅1.浪费计算资源,最后得到的值2.可能还会存在误差。 因此,...
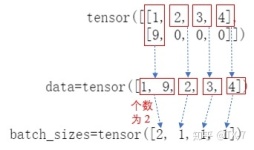

pad_sequence 填充可变长度张量列表 例子 >>> from torch.nn.utils.rnn import pad_sequence >>> a = torch.ones(25, 300) >>> b = torch.ones(22, 300) >>> c = torch....
但是填充后虽然长度相同,但是会有很多无效的填充值,会浪费计算资源为了使 RNN 可以高效的读取数据进行训练,就需要在 pad 之后再使用 pack_padded_sequence 对数据进行处理; input:pad后的序列(由大到小排好序...
该函数用padding_value来填充一个可变长度的张量列表。将长度较短的序列填充为和最长序列相同的长度。,张量的形状为T × B × ∗。否则,张量的形状为B × T × ∗。包含填充序列的张量的元组,以及包含批次中每个...

pack_padded_sequence()与pad_packed_sequence()这两个函数属于torch.nn.utils包中用来处理数据的。前者用于压紧数据,后面用于解压数据。 一. 官方+理解 1. pack_padded_sequence '官方函数' torch.nn.utils.rnn....


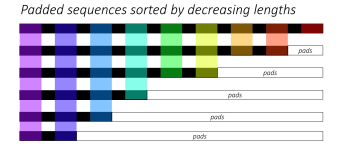
Pytorch中的RNN之pack_padded_sequence()和pad_packed_sequence() 为什么有pad和pack操作? 先看一个例子,这个batch中有5个sample 如果不用pack和pad操作会有一个问题,什么问题呢?比如上图,句子“Yes”只有一个...
跑程序时报错RuntimeError: shape ‘[4, 5, 50, 500]’ is invalid for input of size 450000([4, 5, 45 ,500]),一看知道是维度不一致,发现是出现这torch.view()这里,再往下找发现出现在pad_packed_sequence()...
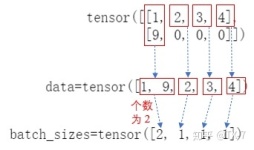
参照https://stackoverflow.com/questions/51030782/why-do-we-pack-the-sequences-in-pytorch import torch from torch import nn seq_batch = [torch.tensor([[1, 1], [2, 2], [3, 3], [4.
nn.utils.rnn.pack_padded_sequence ,nn.utils.rnn.pad_packed_sequence以及 参考https://www.cnblogs.com/lindaxin/p/8052043.html import torch import torch.nn as nn from torch.autograd import Variable...
问题 当我们进行batch个训练数据一起计算的时候,我们会遇到多个训练样例长度不同的情况,这样我们就会很自然的进行padding...主要是用函数torch.nn.utils.rnn.pack_padded_sequence()和torch.nn.utils.rnn.pad_packed
这个函数主要做了两件事: pad 和封装,因为在rnn模型中,一般先将batch中的数据按照一个时间步一个时间步喂入模型的,这个包的主要作用就是将按照样本堆叠的数据,抽取出时间步这个维度重新堆叠。batch_first: ...
RNN之pack_padded_sequence()和pad_packed_sequence()具体使用代码完整展现
pad_packed_sequence是一个PyTorch函数,用于将填充过的序列解包成原始的非填充序列。它接受一个填充过的序列和一个长度列表作为输入,并返回一个元组,其中包含解包后的序列和每个序列的有效长度。这个函数通常用于...
此文章为阐述pytorch中pack_padded_sequence 和pad_packed_sequence的原理 在变长序列文本中,一个batch中的各样本长度可能不一致,在使用RNN模型时,需要填充至统一长度,被填充的位置实际无意义。我们通常取最后一...
以及torch.nn.utils.rnn.pad_packed_sequence() 作用:再用LSTM对句子进行表示时,避免padding对句子表示的影响。 一、为什么RNN需要处理变长输入 假设我们有情感分析的例子,对每句话进行一个感情级别的分类...
nn.utils.rnn.PackedSequence是nn.utils.rnn.pack_padded_sequence的亲戚,两者输出的结果都一样,都是将序列进行pack,得到。第一个是PackedSequence对象,而标准RNN返回的是所有序列,每个位置的隐向量输出,形状...
pytorch中的pad_sequence、pack_padded_sequence和pad_packed_sequence的使用
推荐文章
- zz 圣诞丨太阁所有的免费算法视频资料整理-程序员宅基地
- Linux root初始密码设置_ubuntu设置root用户密码时密码不通过字典检查吧-程序员宅基地
- 【OpenGL】立方体贴图——Cubemap天空盒案例_opengl球体贴图-程序员宅基地
- linux mkfifo 命令_linux 中有名管道mkfifo-程序员宅基地
- [漏洞检查项]Broken Access Control | broken-access-control | 失效的访问控制-程序员宅基地
- DB2数据库一些问题_不能向用editproc定义的表中添加列-程序员宅基地
- html5如何设置div高度,jsp中设置div的高度为页面高度.怎么设置/-程序员宅基地
- 基于Kubernetes的云上机器学习—GPU弹性扩缩容-程序员宅基地
- 杭州程序员对薪酬最满意,上海程序员最辛苦...原来我们是这样的程序员_杭州软件比上海-程序员宅基地
- Unity Shader - 在 URP 获取 Ambient(环境光) 颜色_unity ambient-程序员宅基地