无
”python爬取小说项目概述“ 的搜索结果
基于requests库和lxml库编写的爬虫,目标小说网站域名http://www.365kk.cc/,类似的小说网站殊途同归,均可采用本文方法爬取。
本实战案例涉及使用Python编写一个爬虫程序,用于批量爬取B站(哔哩哔哩)上的小视频。这个案例将使用到requests库来发送HTTP请求,以及BeautifulSoup库来解析网页内容。 适用人群 Python开发者:希望提高网络爬虫...

本次实战项目适合,有一定Python语法知识的小白学员。本人也是根据一些网上的资料,自己摸索编写的内容。有不明白的童鞋,欢迎提问。目的:爬取百度小说吧中的原创小说《猎奇师》部分小说内容链接:...
Python实现的爬取小说爬虫功能示例发布时间:2020-10-09 03:39:58来源:脚本之家阅读:64作者:阳光Cherry梦本文实例讲述了Python实现的爬取小说爬虫功能。分享给大家供大家参考,具体如下:想把顶点小说网上的一篇...
这个分享包涵了我开发的Python爬虫工具项目,主要用于合法爬取某些网页信息。以下是主要内容: 源代码:包括Python代码和相关脚本。这些代码展示了如何使用Python进行网页抓取、解析和数据提取。 项目文件:除了...
目标思路手动浏览前几章节,观察url网址变化,以下为前4章节网址:可以看到,第1和第2章节没有明显...所以,具体的思路为:从第1章开始构造URL,中间有404错误就跳过不爬取。具体代码如下:import requestsimport ...
由于该爬虫实在过于简单,就只简单概述下。 一、请求端 通过观察YY评级的网页信息,如下图(F12或右击进入检查,点击network—>XHR—>headers)。 红色框表明是个get请求(其实这种网页基本都是Ajax get,需要总结...

一、概述 爬取步骤 第一步:获取视频所在的网页 第二步:F12中找到视频真正所在的链接 第三步:获取链接并转换成机械语言 第四部:保存 二、分析视频链接 获取视频所在的网页 以酷6网为例,随便点击一个视频播放链接...


本篇博客将带你学习如何使用Python编写一个简单的网络小说爬虫,从小说网站上爬取小说内容,并实现离线阅读功能。网络小说爬虫是一种自动化获取小说网站上小说内容的程序。通过模拟人的行为,小说爬虫可以自动访问...
本文介绍了使用Python爬取NBA球员数据的示例代码。首先,我们设置了请求头信息和请求地址,并发送HTTP请求获取响应。然后,通过lxml库对响应文本进行解析,并使用XPath表达式提取需要的数据。最后,将结果保存到文件...
主题式网络爬虫名称:爬取全网热点榜单数据2.主题式网络爬虫爬取的内容与数据特征分析:1)热门榜单;2)数据有日期、标题、链接地址等3.主题式网络爬虫设计方案概述:1)HTML页面分析得到HTML代码结构;2)程序实现:a....

它根据网页地址(URL)爬取网页内容,网页地址(URL)就是我们在浏览器中输入的网站链接。例如:https://www.baidu.com;网络爬虫不仅能够复制网页信息和下载音视频,还可以做到网站的模拟登录和行为链执行。由于...
一、概述爬取步骤第一步:获取视频所在的网页第二步:F12中找到视频真正所在的链接第三步:获取链接并转换成机械语言第四部:保存二、分析视频链接获取视频所在的网页以酷6网为例,随便点击一个视频播放链接,比如:...


概述:本文将学习urlopen、BeautifulSoup、urlretrieve三个方法,学习后会在人民网首页爬取8张图片,并下载到本地 2、方法解析 2.1、urlopen 先来看看官方的解释 '''Open the URL url, which can be either a string...
因为新浪微博网页版爬虫比较困难,故采取用手机网页端爬取的方式操作步骤如下:1. 网页版登陆新浪微博2.打开m.weibo.cn3.查找自己感兴趣的话题,获取对应的数据接口链接4.获取cookies和headers# -*- coding: utf-8 -...
主题式网络爬虫设计方案概述(包括实现思路与技术难点):首先找到爬取页面的源代码,找到所需要爬取的数据在源代码中的位置,接下来进行数据爬取,并将数据持久化,接下来对数据进行清洗处理,并进行数据分析和可视化...

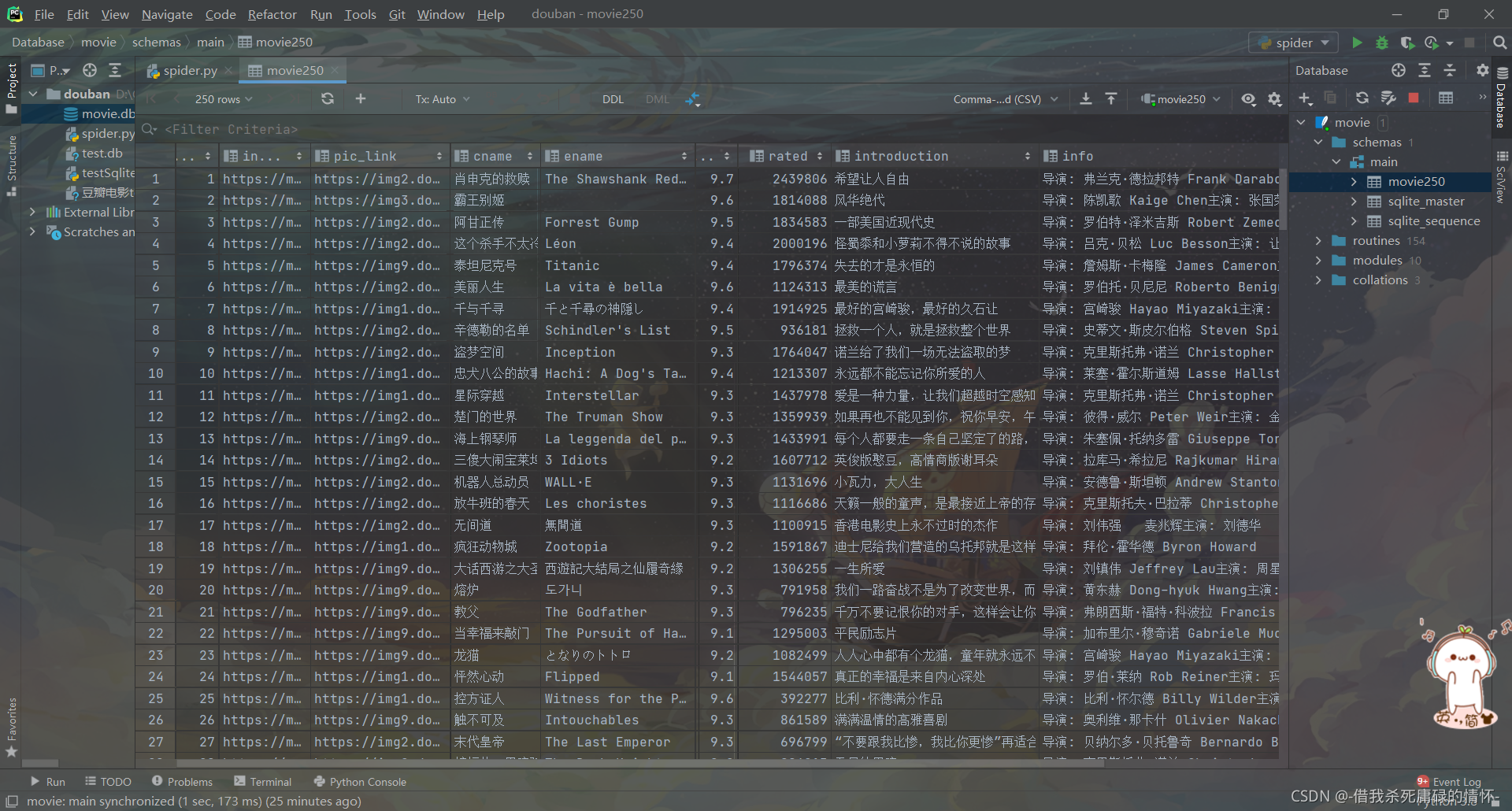
使用Python爬取不同类别的豆瓣电影简介 之前做过一点文本分类的工作,从豆瓣上爬取了不同类别的数千条电影的简介。 爬取目标 我们爬取的目标是 豆瓣影视,打开豆瓣网,随便点击一部电影,即可看到电影的介绍、评论等...
Python爬取数据并存入MongoDB 最近和朋友一起开发APP,需要大量数据,而"互联网"与"共享"融合发展的理念,遂资源的可重用给予了当代骚客文人获得感与幸福感…好了,不日白了(正宗重庆话,吹牛的意思),开始正题 ...

推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地