无
”python爬微博数据合法吗“ 的搜索结果
功能连续爬取一个或多个新浪微博用户(如Dear-迪丽热巴、郭碧婷)的数据,并将结果信息写入文件。写入信息几乎包括了用户微博的所有数据,主要有用户信息和微博信息两大类,前者包含用户昵称、关注数、粉丝数、微博...
微博数据是非常有价值的数据,这些数据可以用作我们进行一些系统开发时的数据源, 比如前段时间发过的:Python 短文本识别个体是否有自杀倾向,在此文中,我们使用微博绝望树洞的数据,利用SVM做了一个简单的自杀...
具体要感谢大神贡献的代码,大神链接代码我做了些修改满足我的需求,以下为代码:# -*- coding: utf-8 -*-import urllib.requestimport jsonfrom pymongo import MongoClientid = '1761179351'MONGO_HOST = 'mongodb...
知识领域: 数据爬取、社交媒体分析、Python编程 技术关键词: Python、...其他说明: 由于微博平台可能存在数据保护和隐私政策限制,用户在使用爬虫时需要遵循相关法律法规和平台政策,确保合法合规同时,爬取数据的质
功能爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片和微博视频(可选)。本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。...
解锁网络数据的宝藏:Python爬虫工具与教程集合 一、探索网络信息的无限宝藏 在互联网的海洋中,蕴藏着海量的有价值信息。如何合法、高效地获取这些信息?Python爬虫工具与教程为您揭开这一神秘面纱。通过这些资源...
功能爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片(可选)。本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。如需免...
解锁网络数据的宝藏:Python爬虫工具与教程集合 一、探索网络信息的无限宝藏 在互联网的海洋中,蕴藏着海量的有价值信息。如何合法、高效地获取这些信息?Python爬虫工具与教程为您揭开这一神秘面纱。通过这些资源...
需要注意的是,爬虫应该在遵守新浪微博平台的使用协议和法律法规的前提下进行,以确保合法合规的数据采集。 请注意,尊重新浪微博平台的规定,不要滥用爬虫程序,避免对平台正常运营造成干扰。同时,确保你的爬虫...
功能爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片和微博视频(可选)。本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。...
爬取微博评论是一种常见的数据获取任务,可以使用Python来实现。根据引用\[1\]中提供的内容,可以使用以下步骤来实现爬取微博评论的功能: 1. 获取微博地址:通过解析页面中的微博地址或者指定用户的微博地址,可以...
基于Python的微博数据爬虫及文本情感分析系统的实现可以通过以下步骤实现: 首先,我们可以使用Python中的第三方库如BeautifulSoup或Scrapy来进行微博数据的爬取。这些库可以帮助我们从微博网站上抓取用户发布的...
你可以使用Python编写爬虫来获取微博数据。以下是一些基本骤: 1. 安装必要的库:使用`pip`命令安装`requests`和`beautifulsoup4`库。 2. 导入库:在Python脚本中导入所需的库。 ```python import requests from ...
功能爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片和微博视频(可选)。本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。...
Python合法网页爬虫工具项目分享 内容概览: 这个分享包涵了我开发的Python爬虫工具项目,主要用于合法爬取某些网页信息。以下是主要内容: 源代码:包括Python代码和相关脚本。这些代码展示了如何使用Python进行...
功能爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片和微博视频(可选)。本程序需要设置用户cookie,以获取微博访问权限,后面会讲解如何获取cookie。...
运行环境开发语言:python2/python3系统: Windows/Linux/macOS以爬取迪丽热巴的微博为例,她的微博昵称为"Dear-迪丽热巴",id为1669879400(后面会讲如何获取用户id)。我们选择爬取她的原创微博。程序会自动...
在示例代码中,首先导入了...6. Scikit-learn:用于机器学习和数据挖掘,可以对采集的数据进行分析和预测。# 在这里进行网页内容的解析和提取所需数据的操作。3. 使用解析库解析网页内容,提取所需的数据。
解锁网络数据的宝藏:Python爬虫工具与教程集合 一、探索网络信息的无限宝藏 在互联网的海洋中,蕴藏着海量的有价值信息。如何合法、高效地获取这些信息?Python爬虫工具与教程为您揭开这一神秘面纱。通过这些资源...
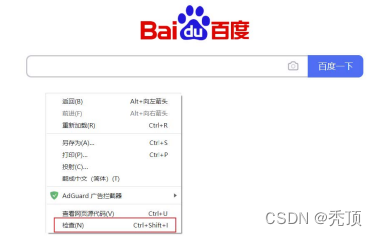
Python微博爬虫是指使用Python编程语言编写的工具或程序,用于自动化地获取微博用户的内容、图片等信息。通过爬取用户关注的其他用户,并不断爬取,直到达到设定的要求。 一个例子是可以使用Python的requests库或...
作者 | 马超来源 | CSDN(ID:CSDNnews)3月19日,默安科技CTO魏兴国发微博称,微博数据泄露了不少用户的手机号,当中涉及不少微博认证...

爬取微博评论以及子评论数据可以通过使用Python的网络爬虫库来实现。首先,需要安装相关的库,例如requests和beautifulsoup。下面是一个简单的代码示例: ```python import requests from bs4 import BeautifulSoup...
大数据毕业设计hadoop+spark+hive微博预警系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 微博大数据 微博推荐系统 微博预测系统 计算机毕业设计 知识图谱 机器学习 深度学习
那么拿到需求我们进到微博网站对进口进行查找,对接口进行抓取的话,能获得数据无疑是最省事安心的方式 2.那么在github上看到写的十分好用的案例,那么本着互联网开源的思想,对代码进行学习修改。 废话不多说,直接...
可以使用Python的第三方库进行微博评论的爬取,下面是一个简单的示例代码: ...需要注意的是,爬取他人的微博内容涉及到隐私和法律问题,请确保在合法范围内使用爬虫技术,并尊重他人的隐私和版权。
推荐文章
- NSFuzz:TowardsEfficient and State-Aware Network Service Fuzzing-程序员宅基地
- 刘睿民畅谈大数据:政府应紧急设立首席数据官-程序员宅基地
- nginx 编译安装依赖包_nginx编译怎么添加新的依赖库-程序员宅基地
- Python+OpenCV+Tesseract实现OCR字符识别_python + opencv + tesseract-程序员宅基地
- 微型计算机主板上的主要部件,微型计算机主板上安装的主要部件-程序员宅基地
- 推荐一款可匹敌国际大厂的国产企业级低无代码平台_国产私有化 无代码-程序员宅基地
- UE4 蓝图 实现 数组的边遍历边删除_ue4 数组删不掉-程序员宅基地
- python爬虫之bs4解析和xpath解析_from bs4 import beautifulsoup xpath-程序员宅基地
- MySQL配置环境变量-程序员宅基地
- VGG16进行微调,训练mnist数据集_vgg16 tensorflow 2 mnist-程序员宅基地