”spark2原理分析“ 的搜索结果
本文讲述了RDD依赖的原理,并对其实现进行了分析。 Dependency的基本概念 Dependency表示一个或两个RDD的依赖关系。 依赖(Dependency)类是用于对两个或多个RDD之间的依赖关系建模的基础(抽象)类。 Dependency有一...
这些面试题分享给大家的目的,其实是希望大家通过大厂面试题分析自己的技术栈,给自己梳理一个更加明确的学习方向,当你准备好去面试大厂,你心里有底,大概知道面试官会问多广,多深,避免面试的时候一问三不知。
ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark...
很多程序员,整天沉浸在业务代码的 CRUD 中,业务中没有大量数据做并发,缺少实战经验,对并发仅仅停留在了解,做不到精通,所以总是与大厂擦肩而过。我把私藏的这套并发体系的笔记和思维脑图分享出来,理论知识与...
本文分析spark2的shuffle过程的实现。 shuffle过程介绍 shuffle总体流程 spark2的shuffle过程可以分为shuffle write和shuffle read。shuffle write把map阶段计算完成的数据写入到本地。而shuffle read是从不同的计算...
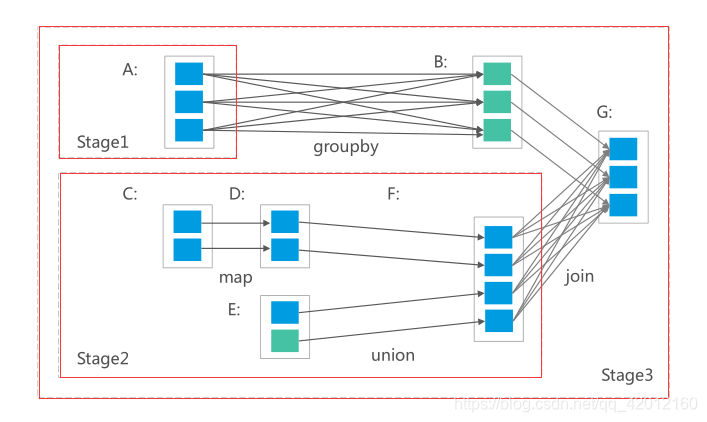
本文介绍RDD的Shuffle原理,并分析shuffle过程的实现。 RDD Shuffle简介 spark的某些操作会触发被称为shuffle的事件。shuffle是Spark重新分配数据的机制,它可以对数据进行分组,该操作可以跨不同分区。该操作通常会...
Grappa的起源是这样的:一群在克雷(Cray)系统上运行大数据任务方面有着丰富经验的工程师想,是不是可以与克雷系统在现成商用硬件上能够实现的分析功能一较高下。如果你有兴趣看看Grappa是怎么实际运行的,可以在应用...
Java架构学习技术内容包含有:Spring,Dubbo,MyBatis, RPC, 源码分析,高并发、高性能、分布式,性能优化,微服务 高级架构开发等等。还有Java核心知识点+全套架构师学习资料和视频+一线大厂面试宝典+面试简历模板...
利用AUC评分最高的参数,给艺术家推荐喜欢他的用户。利用AUC评分最高的参数,给用户推荐艺术家。进行音乐推荐(或用户推荐)计算AUC评分最高的参数。对多个用户进行艺术家推荐。
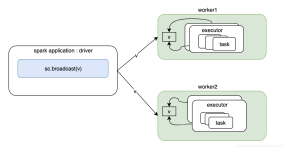
在集群中由Master给应用程序分配运行资源后,然后在Worker中启动 ExecutorRunner ,而 ExecutorRunner根据当前的运行模式启动CoarseGrainedExecutorBackend进程,当该进程会向 Driver 发送注册Executor信息。...
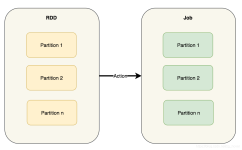
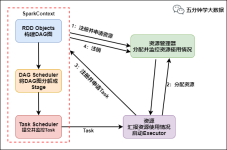
概述 本文介绍Saprk中DAGScheduler的基本概念。该对象实现了一个面向Stage的高层调度器。...在文章《spark2原理分析-Stage的实现原理》中,介绍了Stage的基本概念和Stage的提交实现原理。本文主要介绍 DAGSch...
SparkRPC层是基于优秀的网络通信框架Netty设计开发的,同时获得了Netty所具有的网络通信的可靠性和高效性。我们先把Spark中与RPC相关的一些类的关系梳理一下,为了能够更直观地表达RPC的设计,我们先从类的设计来看...
如果两个推测执行的 shuffle 数据同时达到,由于锁的限制,会先后执行时,后边的请求执行时,currentMapIndex 都...第2部分从所有运行过执行器的 host 中查找,去除第 1 部分中重叠的 host,并且去除加入黑名单的host。
【代码】Spark大数据分析与实战:基于Spark MLlib 实现音乐推荐_基于spark的音乐(3)
利用AUC评分最高的参数,给艺术家推荐喜欢他的用户。利用AUC评分最高的参数,给用户推荐艺术家。计算AUC评分最高的参数。对多个用户进行艺术家推荐。
ESS 要把收到的多个 mapper 的同一个 shuffle partition 的数据进行合并, Merger Location 就是进行合并的这些 ESS 的地址。1): 把 shuffle 数据分为Seq[PushRequest], 一个 PushRequest 代表一个目标位置的数据一...
Spark Codegen是在CBO&RBO后,将算子的底层逻辑用代码来实现的一种优化。 具体包括Expression级别和WholeStage级别的Codegen。 2、举例说明 ① Expression级别:摘一个网上的例子:x + (1 + 2) 用scala代码表示...
ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark...
Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如何处理代码分布式执行问题的资料少之又少,这也是我撰写文本的目的。Spark运行在...
本系列目录如下: 数据类型 基本统计 summary statistics(概括统计) correlations(相关性系数...PCA(主成分分析) 特征抽取和转换 特征抽取 TF-IDF Word2Vec CountVectorizer 特征转换 Tokenizer StopWordsRemo
本文首先对决策树算法的原理进行分析并指出其存在的问题,进而介绍随机森林算法。同单机环境下的随机森林构造不同的是,分布式环境下的决策树构建如果不进行优化的话,会带来大量的网络IO操作,算法效率将非常低,...
公众号后台回复“图书“,了解更多号主新书内容作者:livan来源:数据python与算法 hadoop的MR结构和YARN结构是大数据时代的第一代产品,满足了大家在离线计算上的需求,但...
spark内部原理介绍
标签: spark
基于RDD的架构,在这个开源系统栈里包括作为公共组件的Apache Spark;处理SQL的Shark;和处理分布式流的Spark...我们的实现为传统和新的数据分析工作提供了很好的性能,并成为第一个使得用户可以组合这些计算任务的平台。
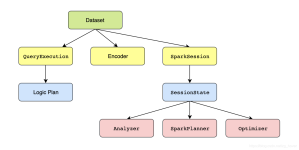
本文讲述Spark Dataframe的原理要点。 Dataframe原理要点 Spark SQL引入了一个名为DataFrame的表格函数数据抽象。设计它的目的在于:简化Spark应用程序的开发。这样就可以在Spark基础架构上处理大量结构化表格数据...
, 《深入理解SPARK:核心思想与源码分析》一书对Spark1.2.0版本的源代码进行了全面而深入的分析,旨在为Spark的优化、定制和扩展提供原理性的指导。阿里巴巴集团专家鼎力推荐 、阿里巴巴资深Java开发和大数据专家...
推荐文章
- maven 如何查看jar在哪个pom引入_maven查看jar包从哪个pom引入-程序员宅基地
- handsontable合并项mergeCells应用及扩展-程序员宅基地
- Object.requireNonNull_objects.requirenonnull-程序员宅基地
- python提取pdf中图片和文本_python原生代码,提取pdf图片中的文字-程序员宅基地
- 计算机二级office考试题库操作题,计算机二级考试MSOffice考试题库ppt操作题附答案...-程序员宅基地
- unity 启动相机_Unity3D研究院之打开照相机与本地相册进行裁剪显示(三十三)...-程序员宅基地
- oracle sql 分区查询语句_oracle表空间表分区详解及oracle表分区查询使用方法-程序员宅基地
- 国培 计算机远程培训心得,信息技术国培学习心得体会(2)-程序员宅基地
- oracle博客管理系统,读赵杰夫博客之ORACLE EBS 系统主数据管理(A)摘录-程序员宅基地
- java实现会员注册_java wed【上机作业】会员注册,利用request对象。(1)首先判断密码长度要在5~1-程序员宅基地