”spark2实现原理分析“ 的搜索结果
本系列目录如下: 数据类型 基本统计 summary statistics(概括统计) correlations(相关性系数...PCA(主成分分析) 特征抽取和转换 特征抽取 TF-IDF Word2Vec CountVectorizer 特征转换 Tokenizer StopWordsRemo
_shuffleTimeout: 如果没有 shuffle数据,为 0, 否则为参数 spark.dynamicAllocation.shuffleTracking.timeout 的值(默认 Long.MaxValue)。每个 executor 用一个集合 shuffleIds 存储其上拥有的 shuffle 数据。
如果两个推测执行的 shuffle 数据同时达到,由于锁的限制,会先后执行时,后边的请求执行时,currentMapIndex 都...第2部分从所有运行过执行器的 host 中查找,去除第 1 部分中重叠的 host,并且去除加入黑名单的host。
本文介绍了Dataset检查点机制(checkpoint)的实现原理,并对其源码进行了分析。
ExecutorMonitor 为每个 Executor 创建一个 Tracker, 用于跟踪此 Executor 的状态。定时任务间隔时间查找 timeout 的 executor,然后处理。timedOutExecutors 方法的主要逻辑,就是遍历 executors。...
spark-ml-source-analysis:spark ml算法原理剖析以及具体的源码实现分析
如果 executor 没有 active 的 shuffle 并且当前时间大于 executor 的超时时间 timeoutAt,则此 executor 可以被安全释放。并且启动定时任务,定时扫描每个 Executor,判断是否有任务运行,是否有 active 的 shuffle...
本文讲述Spark Dataframe的原理要点。 Dataframe原理要点 Spark SQL引入了一个名为DataFrame的表格函数数据抽象。设计它的目的在于:简化Spark应用程序的开发。这样就可以在Spark基础架构上处理大量结构化表格数据...
如果两个推测执行的 shuffle 数据同时达到,由于锁的限制,会先后执行时,后边的请求执行时,currentMapIndex 都等于当前 map 的 index,也不会有问题。如果最后一个 网络 block 仅有部分内容是当前 rpc 的,会限定 ...
如果两个推测执行的 shuffle 数据同时达到,由于锁的限制,会先后执行时,后边的请求执行时,currentMapIndex 都等于当前 map 的 index,也不会有问题。当开启shuffle merge 时,第一个 block(仅一个) 是 ...
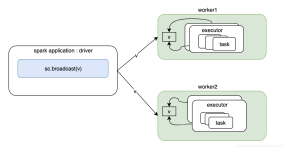
本文分析spark2的shuffle过程的实现。 shuffle过程介绍 shuffle总体流程 spark2的shuffle过程可以分为shuffle write和shuffle read。shuffle write把map阶段计算完成的数据写入到本地。而shuffle read是从不同的计算...

学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
如果两个推测执行的 shuffle 数据同时达到,由于锁的限制,会先后执行时,后边的请求执行时,currentMapIndex 都...第2部分从所有运行过执行器的 host 中查找,去除第 1 部分中重叠的 host,并且去除加入黑名单的host。
本文介绍Dataset的UDF的实现原理。UDF是User-Defined Functions的简写。用户可以根据自己的需要编写函数,并用于Spark SQL中。但也要注意,Spark不会优化UDF中的代码,若大量使用UDF可能让数据处理的性能受到影响,...
Spark RPC实现原理分析
标签: spark
本文主要对Spark RPC的实现进行了宏观(整体架构)和微观(核心源码)上的分析,主要文章结构主要分为模块架构、核心组件和交互流程。
零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
ESS 要把收到的多个 mapper 的同一个 shuffle partition 的数据进行合并, Merger Location 就是进行合并的这些 ESS 的地址。1): 把 shuffle 数据分为Seq[PushRequest], 一个 PushRequest 代表一个目标位置的数据一...
通过学习Spark,我掌握了分布式数据处理的基本原理和技巧,并通过实践应用到了大规模数据集的处理中。通过学习Spring Boot,我了解了现代化的Java Web开发方式,并通过实践构建了一些简单的Web应用程序。我还意识到...

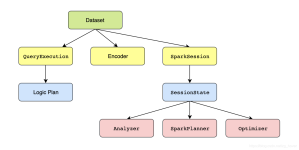
本文分析Dataset中的执行计划的处理过程。执行计划的处理包括以下几个过程:分析逻辑执行计划->优化逻辑执行计划->生成一个或多个物理执行计划->优化物理执行计划->生成可执行代码。 这个过程都是在...
《Spark技术内幕:深入解析Spark内核架构设计与实现原理》以源码为基础,深入分析Spark内核的设计理念和架构实现,系统讲解各个核心模块的实现,为性能调优、二次开发和系统运维提供理论支持;本文最后以项目实战的...
Spark Codegen是在CBO&RBO后,将算子的底层逻辑用代码来实现的一种优化。 具体包括Expression级别和WholeStage级别的Codegen。 2、举例说明 ① Expression级别:摘一个网上的例子:x + (1 + 2) 用scala代码表示...
本文介绍介绍SparkPlanner的实现原理。 SparkPlanner将优化后的逻辑执行计划转换为物理执行计划的计划器(Planner)。 SparkPlanner是一个具体的Catalyst Query Planner,它使用执行计划策略( execution planning ...
Spark是基于内存的分布式计算框架。在迭代计算的场景下,数据处理过程中的数据可以存储在内存中,提供了比MapReduce高10到100倍的计算能力。Spark可以使用HDFS作为底层...Spark2x的开源新特性请参考Spark2x开源新特性。
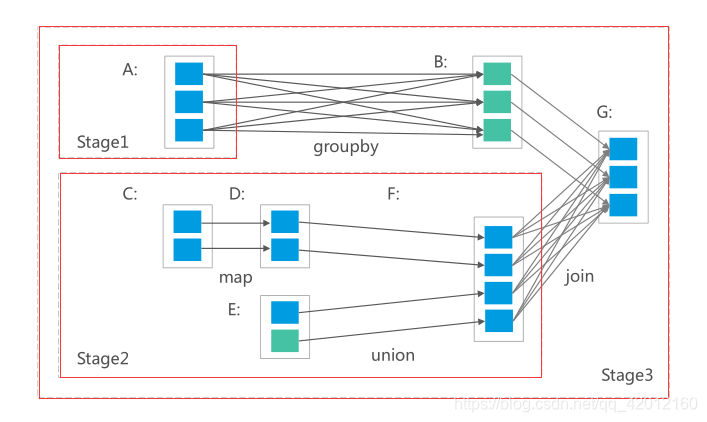
一、shuffle原理分析 1.1 shuffle概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂。 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据...
本书以源码为基础,深入分析spark内核的设计理念和架构实现,系统讲解各个核心模块的实现,为性能调优、二次开发和系统运维提供理论支持,为更好地使用Spark Streaming、MLlib、Spark SQL和GraphX等奠定基础。
推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地