
”spark原理分析“ 的搜索结果
Apache Spark是用于大规模数据处理的统一分析引擎,基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。 Spark源码从1.x的40w行...
ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark...
1Spark原理分析 --RDD的Partitioner原理分析 2Spark原理分析 --RDD的shuffle简介 3Spark原理分析 --RDD的shuffle框架的实现概要分析 4Spark原理分析 --RDD的依赖(Dependencies)原理分析 5Spark原理分析 --RDD的...
SparkRPC层是基于优秀的网络通信框架Netty设计开发的,同时获得了Netty所具有的网络通信的可靠性和高效性。我们先把Spark中与RPC相关的一些类的关系梳理一下,为了能够更直观地表达RPC的设计,我们先从类的设计来看...
本文首先对决策树算法的原理进行分析并指出其存在的问题,进而介绍随机森林算法。同单机环境下的随机森林构造不同的是,分布式环境下的决策树构建如果不进行优化的话,会带来大量的网络IO操作,算法效率将非常低,...
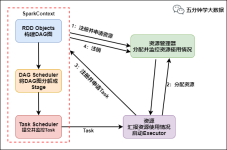
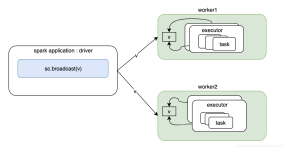
Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如何处理代码分布式执行问题的资料少之又少,这也是我撰写文本的目的。Spark运行在...

ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark...
spark内部原理介绍
标签: spark
基于RDD的架构,在这个开源系统栈里包括作为公共组件的Apache Spark;处理SQL的Shark;和处理分布式流的Spark...我们的实现为传统和新的数据分析工作提供了很好的性能,并成为第一个使得用户可以组合这些计算任务的平台。
本系列目录如下: 数据类型 基本统计 summary statistics(概括统计) correlations(相关性系数...PCA(主成分分析) 特征抽取和转换 特征抽取 TF-IDF Word2Vec CountVectorizer 特征转换 Tokenizer StopWordsRemo
Spark Codegen是在CBO&RBO后,将算子的底层逻辑用代码来实现的一种优化。 具体包括Expression级别和WholeStage级别的Codegen。 2、举例说明 ① Expression级别:摘一个网上的例子:x + (1 + 2) 用scala代码表示...
公众号后台回复“图书“,了解更多号主新书内容作者:livan来源:数据python与算法 hadoop的MR结构和YARN结构是大数据时代的第一代产品,满足了大家在离线计算上的需求,但...

ApacheSpark是一个围绕速度、易用性和复杂分析构建的大数据处理框架,最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apache的开源项目之一,与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark...

spark-ml-source-analysis:spark ml算法原理剖析以及具体的源码实现分析
Hive on Spark源码分析,实际场景中会遇到需求:将Hive默认的执行引擎MapReduce换成Spark或者Tez。
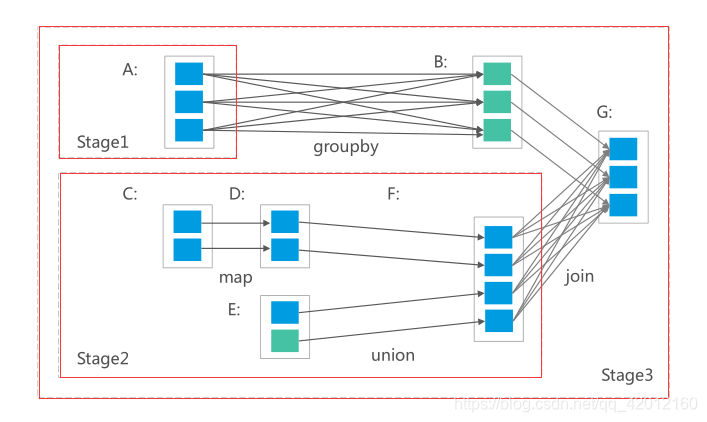
一、shuffle原理分析 1.1 shuffle概述 Shuffle就是对数据进行重组,由于分布式计算的特性和要求,在实现细节上更加繁琐和复杂。 在MapReduce框架,Shuffle是连接Map和Reduce之间的桥梁,Map阶段通过shuffle读取数据...

, 《深入理解SPARK:核心思想与源码分析》一书对Spark1.2.0版本的源代码进行了全面而深入的分析,旨在为Spark的优化、定制和扩展提供原理性的指导。阿里巴巴集团专家鼎力推荐 、阿里巴巴资深Java开发和大数据专家...
Apache Spark是用于处理的统一(unified)分析引擎,其特点就是对任意类型的数据进行自定义计算。
推荐文章
- 发现电脑一直默认按住Ctrl键如何解决_键盘一直自动按ctrl-程序员宅基地
- Linux 命令【6】:cut_cut使用特殊字符为分隔符-程序员宅基地
- 音频进度条设置_audiotrack可以设置进度吗-程序员宅基地
- Sora----打破虚实之间的最后一根枷锁----这扇门的背后是人类文明的晟阳还是最后的余晖-程序员宅基地
- 大批量数据分批式导出文件解决,避免OOM(多次查询多次导出形成一个文件)_bufferedwriter避免oom-程序员宅基地
- 如何生成HLS协议的M3U8文件-程序员宅基地
- Oracle游标:处理查询结果集的好工具_oracle查询游标结果集-程序员宅基地
- 计算机主机箱内的硬件设备主要有哪些,电脑主机有哪些硬件设备-程序员宅基地
- Oracle触发器原理、创建、修改、删除_用oracle创建一个instead of触发器,当在course表中删除数据,不允许在course-程序员宅基地
- 计算机科学与技术网上书店,计算机科学与技术毕业论文:基于web的网上书店.doc...-程序员宅基地