自然语言文本预处理、TF-IDF算法详解(三个维度:原理、流程图、代码)、好玩的中文关键词“词云生成”(解决乱码问题)# 获取停用词# 加载文档集,对文档集过滤词性和停用词# 使用TF-IDF提取关键词# 将过滤后的文档...
”tf-idf“ 的搜索结果

统计十篇新闻TF-IDF 统计TF-IDF词频,每篇文章的 top10 的高频词存储为 json 文件 TF-IDF TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法...
文本相似度分析
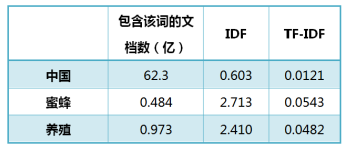
IF-IDF概念 TF-IDF是NLP中常用的方法,也比较经典。IF-IDF的思想:如果一个词在文档中出现了很多次,但是这个词在其它文档中出现的次数很...TF-IDF就是tf−idf(t,d)=tf(t,d)×idf(t)tf-idf(t,d)=tf(t,d) \times idf(...
tf-idf_tf-idf_
标签: tf-idf
tf-idf算法简单分析多个pdf文件关键词
1、TF-IDF算法介绍 TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。 TF-IDF是一种统计方法,...
TF-IDF
#TF-IDF任务给定查询字符串q和文档语料库,请使用tf-idf检索与查询字符串最匹配的前k个文档数据集在文件dataset.txt中有一个板球评论单位列表。 板球评论的一个单位是1个球的评论,它构成1个文件。 在执行程序之前...
Keyword extraction based on TF-IDF of specific corpus. 基于特定语料库的TF-IDF的中文关键词提取
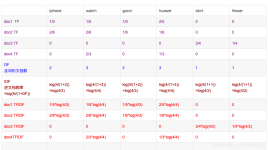
在我们得到词频(TF)和逆文档频率(IDF)以后,将两个值相乘,即可得到一个词的TF-IDF值,某个词对文章的重要性越高,其TF-IDF值就越大,所以排在最前面的几个词就是文章的关键词。 TF-IDF算法的优点是简单快速,...
TF-IDF算法示例代码
标签: 示例 算法
# TF-IDF算法示例 # 0.引入依赖 import numpy as np import pandas as pd import math # 1.定义数据和预处理 docA = The cat sat on my bed docB = The dog sat on my knees bowA = docA.split( ) bowB = docB.split...
TF-IDF:NLP中的TF_IDF的公式,并与Sklearn中的结果进行比较
基于特定语料库的TF-IDF的中文关键词提取 使用前按照说明操作。
基于Word2vec和改进TF-IDF算法的深度学习模型研究.pdf
<<<<<<< HEAD 样本-LDA-scala 来自lda的克隆版本-databricks的示例 tf-idf-spark-sample 样本TF-IDF算法使用spark + scala 33379db2c1920758c21caa369908e7ba86c39e6a
基於python的中文小说/文件tf-idf实现.zip,Term frequency–inverse document frequency for Chinese novel/documents implemented in python.
本实验文档详细叙述了TF-IDF算法原理、伪代码、TF矩阵的构造、IDF向量的构造、TF-IDF矩阵的计算和文件输出以及实验结果的分析这些内容,希望对大家有所帮助。
实现基于TF-IDF算法抽取,对关键词进行抽取的算法,程序
基于TF-IDF算法和LDA主题模型数据挖掘技术在电力客户抱怨文本中的应用.pdf
udicTfidf 使用Wikipedia语料库的TF-IDF模型正在安装(推荐):使用安装手动安装如果要将udicTfidf集成到自己的django项目中,请使用手动安装。 pip install udicTfidf设定档在settings.py添加Django应用udicTfidf ...
TF-IDF是关键词提取中常用的手段,但是它仅仅考虑了特征词在文本中的词频和逆文档率,没有考虑到特征词在类内和类间中的分布情况,依然有很大的改进空间。而TF-IDF-CI就是对TF-IDF的一种改进方式。
主要为大家详细介绍了TF-IDF与余弦相似性的应用,找出相似文章,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
基于改进TF-IDF的多态蠕虫特征自动提取算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。比较容易理解的一个应用场景是当我们手头有一些文章时,我们希望...
在使用TF-IDF算法进行自然语言处理时,大家在处理文本时会首先进行切割,生成包含所有词的词典,但此时往往会有许多重复的词,这些词可能是经常使用的词,比如”的“,这样的词语太多会影响处理效果,因此需要去掉...
Tfidf:为每个查询字词计算tf-idf
本节介绍 基于ngram-tf-idf的余弦距离计算相似度。 本节将介绍两种实现:基于sklearn 和 基于gensim 基于sklearn的方式如下: import os import re import jieba import pickle import logging import numpy
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地