FusionAD,基于BEV的多模态、多任务、端到端自动驾驶模型,专注于自动驾驶预测和规划任务,性能超越2023 CVPR最佳论文UniAD模型。
”传感器深度学习融合论文精读“ 的搜索结果
作者上来就说视觉文本的预训练任务,缩写为VLP任务,在过去几年发展的不错,在各种各样的视觉文本的下游任务上都取得了很好的成绩。但是之前的这些方法,为了在那些下游任务上获得很好的结果,大家发现往往你在视觉...
Multi-GNSS PPP/INS/Vision/LiDAR tightly integrated system for precise navigation in urban environments



深度学习经典、新论文逐段精读

所以说对于自监督学习来说,不论你是对比学习还是最新的掩码学习,大家接下来都是用 vision Transformer 去做的. 当然肯定还有很多其他优秀的工作了。鉴于时间关系,我们这里只是把最有联系的一些工作串到一起,讲讲...
在此仅做翻译(经过个人修改,有基础的话应该不难理解),有时间会有详细精读笔记。由于其高时间分辨率、增强的运动模糊恢复能力和非常稀疏的输出,事件摄像机已被证明是低延迟和低带宽特征跟踪的理想选择,即使在...


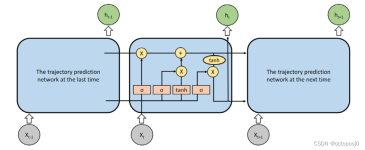
TDNet
论文只选了那些单目图像的深度学习方法,上部主要是半年以前的论文。 •PoseCNN: A CNN for 6D ObjectPoseEstimation in Cluttered Scenes (RSS 2017) 估计已知目标的6D姿势对于机器人与现实世界进行交互非常...


提高对数据丢失的鲁棒性已成为多模态情感分析(MSA)的核心挑战之一,在当前的...首先,采用基于模态内和模态间注意力的提取器来学习模态序列中每个元素的鲁棒表示。然后,提出了一个重构模块来生成缺失的模态特征。
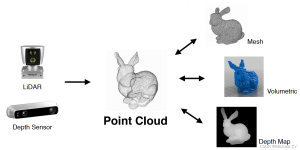

Point-LIO: Robust High-Bandwidth Light Detection and Ranging Inertial Odometry
自动驾驶技术过去10年发展迅速,实现全自动驾驶依然是一项艰巨的任务深度学习和计算机视觉的突破带来了自动驾驶的迅速发展,然而自动驾驶的潜力尚未完全发挥,虽然在受限受控环境中已经得到了应用,但是在城市环境中...
《EnlightenGAN: Deep Light Enhancement withoutPaired Supervision》论文超详细解读(翻译+精读)
大四开始了,你可以开始深挖自己的研究方向,同时也要开始学一些高级一点的通用技术和理论,这时候你和一般的机械、电子、计算机学生就不太一样了,你虽然也在狂编程,但也在狂学习物理和数学。...
作者 | 汽车人编辑 | Autobox目前,公众号正向大家广泛征稿中,欢迎童鞋们投稿,我们将有一定的稿费支持哦,详细信息请点击:汽车人,快来投稿了!数据集COO: Comic Onomatopoeia Dataset for Recognizing Arbitrary...
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地