
”数据平衡“ 的搜索结果
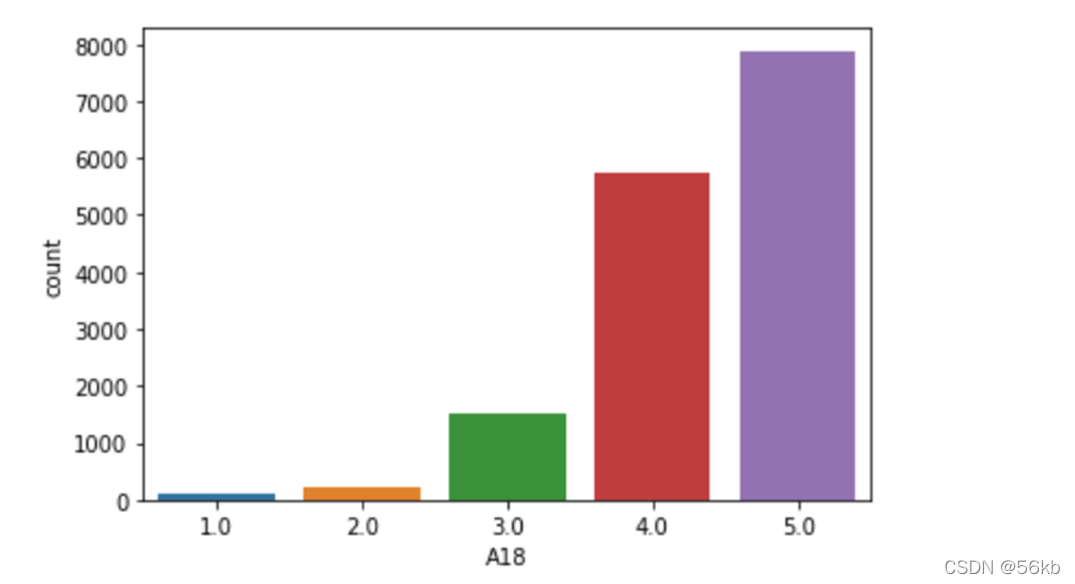
某种样本数量远小于另一种样本数量:数据采样方法(随机过/欠采样,SMOTE,OSS),数据增强。
该数据集为航空运营中广泛使用的各种飞机模型提供了重量和平衡信息的全面汇编。该数据集经过精心策划,包含对保证飞机安全高效运行至关重要的重要参数。通过在飞行过程中精心管理重量分布和平衡,航空利益相关者可以...
一、不平衡数据集的定义所谓的不平衡数据集指的是数据集各个类别的样本量极不均衡。以二分类问题为例,假设正类的样本数量远大于负类的样本数量,通常情况下通常情况下把多数类样本的比例接近100:1这种情况下的数据...
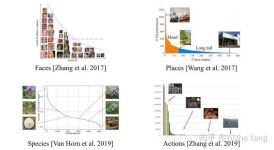
长尾问题 数据不平衡 学习笔记
标签: 数据不平衡
<name>dfs.datanode.fsdataset.volume.choosing.policy</name> <value>org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy</value>
不平衡数据集:数据集各个类别的样本数目差距过大不平衡数据的学习即需要在分布不均匀的数据集中学习到有用的信息。
一、下采样 ...从多数类中随机抽取样本(抽取的样本数量与少数类别样本量一致)从而减少多数类别样本数据,使数据达到平衡的方式。 import numpy as np import pandas as pd def lower_sam...
不平衡数据的定义2. 解决不平衡数据的方法2.1 欠采样2.2 过采样2.3 阈值移动2.4 扩大数据集2.5 尝试对模型进行惩罚2.6 将问题变为异常点检测2.7 特殊的集成的方法2.8 改变评价指标 1. 不平衡数据的定义 大多数分类...
非平衡数据(Imbalanced Data)指的是在一个数据集中,不同类别的样本数量极不相等。在一个典型的非平衡数据场景中,一个或少数几个类别(称为多数类)的样本数量远远超过其他类别(称为少数类)的样本数量。这种...
二叉查找树又名二叉排序树,亦称二叉搜索树。是每个结点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。
即类别不平衡,为了使得学习达到更好的效果,因此需要解决该类别不平衡问题。Jason Brownlee的回答:原文标题:8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset 当你在对一个类别不...

首先,我们准备了多分类和不平衡的数据集,然后通过类别权重处理不平衡数据,最后使用XGBoost进行多分类任务,并评估了模型的性能。通过这篇博客教程,您可以详细了解如何在Python中使用XGBoost处理多分类和不平衡...
国研究生数学建模竞赛F题-飞行器质心平衡供油策略优化python源码+文档说明+数据 - 不懂运行,下载完可以私聊问,可远程教学 该资源内项目源码是个人的参赛作品,代码都测试ok,都是运行成功后才上传资源,放心下载...
本文只对已经安装好cdh的虚拟机节点加入集群平衡数据操作。 1、查看虚拟机 virsh list -all 2、修改虚拟机的配置(CPU、内存、磁盘) 切换到相应虚拟机目录下 cd /ecars/vm/cdhslave07 vim libvirt.xml 3、...
引言 不管是在学术界还是工业界,不平衡学习已经吸引了越来越多的关注,不平衡...那么什么是不平衡数据呢?顾名思义即我们的数据集样本类别极不均衡,以二分类问题为例,假设我们的数据集是$S$,数据集中的多数类为
本文本是广东工业大学数据结构课设平衡二叉树的演示的报告,最后的等级是优秀。文本里面对于选做提高的部分内容都采用了两种方法实现。文档里面有些过程的演示由于涉及到个人信息我删除了,你们可以下载下来后可以...
例如,Retina-100K数据集有75,714个训练样本,9,335个验证样本,9,477个测试样本,共53个类别,不平衡比例是828.56,标签基数是1.3439,标签密度是0.0038。如果一个样本可能同时包含多种视网膜疾病的标签,例如...
数据不平衡问题虽然不是最难的,但绝对是最重要的问题之一。 一、数据不平衡 在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法...

平衡二叉树也叫AVL树,它或者是一颗空树,或者具有以下性质的二叉排序树:它的左子树和左子树的高度之差(平衡因子)的绝对值不超过1,且它的左子树和右子树都是一颗平衡二叉树。 二、结构 如基本概念所树,它具有一...

在处理不平衡的数据集时,如果类不能与给定变量很好地分离,并且我们的目标是获得最佳的准确性,则最佳分类器可以是始终回答多数类的“幼稚”分类器
问题定义那么什么是不平衡数据呢?顾名思义即我们的数据集样本类别极不均衡,以二分类问题为例,假设我们的数据集是$S$,数据集中的多数类为$S_maj$,少数类为$S_min$,通常情况下把多数类样本的比例为$100:



balanced和unbalanced面板数据到底有什么区别?是只要面板数据中有缺失值就算unbalanced数据吗?另外,除了这两种输入方式有些不同外,是不是对于eviews中面板数据相关的分析方法,这两种数据都可以用?另外,在...
推荐文章
- 1N5819-ASEMI轴向肖特基二极管1N5819-程序员宅基地
- 把maven的setting配置文件改为需要jdk版本_<profile> <id>jdk-1.4</id> <activation> <jdk>1.4</-程序员宅基地
- 使用matlab进行DBscan聚类_dbscan聚类分析图用什么软件-程序员宅基地
- 探秘技术新星:BBS_admin - 一个现代化的论坛后台管理系统-程序员宅基地
- 【译】JavaScript 开发者年度调查报告-程序员宅基地
- 神仙级渗透测试入门教程(非常详细),从零基础入门到精通,从看这篇开始!_网络渗透技术自学-程序员宅基地
- 多个protocbuf版本切换_protobuf调整版本-程序员宅基地
- msf+cobaltstrike联动(一):把msf的session发给cobaltstrike-程序员宅基地
- C语言--编写程序,输入一个整数,判断它能否被3,5,7整除_编程序实现功能:输入一个整数,判断其是否能同时被3、5、7整除。能被整除则输出“y-程序员宅基地
- 数据技术之Hadoop(HFDS文件系统)-程序员宅基地