数据集中个人收入低于5万美元的数据比高于5万美元的数据要明显多一些,存在着一定程度的分布不平衡。 针对这一数据集,可以使用很多不平衡分类的相关算法完成分类任务。 如何为数据分布不平衡的成人收入数据集开发...
”数据平衡“ 的搜索结果
如果不考虑数据平衡的问题,模型的性能会出现问题。 原因: 1.对于不平衡类别,模型无法充分考察样本,从而不能及时有效地优化模型参数。 2.它对验证和测试样本的获取造成了一个问题,因为在一些类观测极少的情况下...
一般来说,不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这样模型在测试数据上的泛化能力就会受到影响。一个例子,训练集中有99个正例样本,1个负例样本。在不考虑样本不平衡的很...

文章目录概述定义传统分类器对于不平衡数据的不适用性可应用领域分类方法总框架数据层面样本采样技术随机采样技术人工采样技术经典过采样方法经典欠采样方法其他方法:特征层面Filter过滤式Wrapped封装式Embedded...

1. 不平衡数据的定义 在分类问题中,类别之间的分布不均匀导致数据的不平衡。比如,针对二分类问题,target取值为0和1,当其中一方(如y=1)的占比远小于另一方(y=0)的时候,就构成了不平衡数据。 那么到底是需要...
1.数据不平衡1.1 数据不平衡介绍数据不平衡,又称样本比例失衡。对于二分类问题,在正常情况下,正负样本的比例应该是较为接近的,很多现有的分类模型也正是基于这一假设。但是在某些特定的场景下,正负样本的比例却...
当CEPH 数据不一致时,需要对ceph pg的数据进行平衡 1:检查数据分布是否均衡 #查看osd使用情况 # # ceph osd df tree #查看osd_num,PGS, %USE # ceph osd df tree | awk '/osd\./{print...
1、过采样、欠采样的方式对不平衡的正负样本进行采样。 2、正负样本各自在进行训练时,设置不用的惩罚系数。 2、集成的方式:例如,在数据集中的正、负样本分别为100和10000,比例为1:100。此时可以将负样本(类别...
文章目录本章概述一、不平衡数据是什么?二、数据说明三、不平衡数据的配平1.向下抽样2.向上抽样四、不平衡数据配平的影响 本章概述 本章节主要是阐述一下不平衡数据的定义,并且运用向下抽样和向上抽将数据进行...


在机器学习和数据科学中,我们经常遇到一个称为不平衡数据分布的术语,通常发生在其中一个类中的观察值远高于或低于其他类时。由于机器学习算法倾向于通过减少误差来提高准确性,因此它们不考虑类分布。这个问题在...

目录分层抽样分层抽样示例上采样下采样分层比例/定额抽样原理, 参考:按比例分层抽样和定额抽样的区别? - 知乎(比例)分层抽样是概率抽样的一种,是指先分层再按总体群种中各层的比例随机抽样。...
浅谈不平衡数据集的处理方法
标签: 机器学习

不平衡数据集的部分分类或分类问题,是机器学习中的一个基本问题,收到广泛的关注。主要从三个级别进行考虑 提示:以下是本篇文章正文内容,下面案例可供参考 一、pandas是什么? 示例:pandas 是基于NumPy 的一种...
1.数据不平衡 1.1 数据不平衡介绍 数据不平衡,又称样本比例失衡。对于二分类问题,在正常情况下,正负样本的比例应该是较为接近的,很多现有的分类模型也正是基于这一假设。但是在某些特定的场景下,正负样本的比例...
机器学习之不平衡数据集的处理方法1,不平衡数据集1.1 定义1.2 举例1.3 实例1.4 导致的问题2. 不平衡数据集常用的处理方法2.1 扩充数据集2.2 对数据集进行重采样 1,不平衡数据集 1.1 定义 不平衡数据集指的是数据集...
不平衡学习是机器学习问题的一个重要子域,其主要关注于如何从类别分布不均衡的数据中学习数据的模式。在这篇文章中我们主要关注不平衡分类问题,特别地,我们主要关注类别极端不平衡...
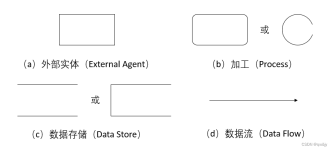
一、数据流图 ( DFD ) 简介 、 二、数据流图 ( DFD ) 概念符号 、 1、数据流 、 2、加工 ( 核心 ) 、 3、数据存储 4、外部实体 、 三、数据流图 ( DFD ) 分层 、 1、分层说明 、 2、顶层数据流图 、 3、中层数据流图...


类别失衡会给预测任务带来挑战,并且会导致少数类别的预测效果较差因为大部分机器学习算法的假设场景是类别(数据)平衡的前提。 本文原始链接 MLSMOTE 分类是一种有监督学习技术,是将目标数据分类至提前已经定义...

如何处理数据不平衡问题
标签: 机器学习
一、什么是数据不平衡问题 数据不平衡也可称作数据倾斜。在实际应用中,数据集的样本特别是分类问题上,不同标签的样本比例很可能是不均衡的。因此,如果直接使用算法训练进行分类,训练效果可能会很差。 二、如何...
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地