BLOOM 的模型架构与GPT3非常相似,只是增加了一些改进,本文稍后将对此进行讨论。该模型是在Jean Zay上训练的,Jean Zay 是由 GENCI 管理的法国政府资助的超级计算机,安装在法国国家科学研究中心 (CNRS) 的国家计算...
”模型并行与数据并行“ 的搜索结果
例如下面是一个使用TensorFlow进行数据并行训练的简单例子,假设有一个简单的多层感知机(MLP)模型,我们将使用模型并行和数据并行来训练它。模型并行和数据并行是处理大型深度学习模型训练中的两种重要策略,它们...
个人总结能实现多GPU跑图的方法: 1、使用谷歌框架tf.estimator; session_config = tf.ConfigProto(device_count={'GPU': 0,'GPU':1,'GPU':2,'GPU':3}) run_config = tf.estimator.RunConfig().replace(session_...
在深度学习这一领域经常涉及到模型的分布式训练(包括一机多GPU的情况)。我自己在刚刚接触到一机多卡,或者分布式训练时曾对其中到底发生了什么有过很多疑问,后来查看了很多资料,在这篇博客里对分布式的深度学习...
在人工智能大模型技术的研究与开发中,模型并行和数据并行是两种经典且有代表性的方法。这两个方法可以极大的提升机器学习系统的性能,对海量数据的处理速度有显著的提升。本文将简要介绍一下这两类技术,以及它们...
任务并行编程模型是近年来多核平台上广泛研究和使用的并行编程模型,旨在...然后,从3 个角度,即并行性表达、数据管理和任务调度介绍任务并行编程模型的研究问题、困难和最新研究成果;最后展望了任务并行未来的研究方向.
本文将深入探讨Megatron-DeepSpeed中的模型并行与数据并行,并通过实例和图表解释这些抽象的技术概念。让我们一起探索如何在大规模语言模型训练中实现高效并行,以加速模型的开发和部署。
模型并行( **model parallelism** ):分布式系统中的不同机器(GPU/CPU等)负责网络模型的不同部分 —— 例如,神经网络模型的不同网络层被分配到不同的机器,或者同一层内部的不同参数被分配到不同机器;...
大模型并行训练、超大模型分布式训练
标签: 分布式
提供了对大规模模型进行并行训练的能力,支持模型并行和数据并行,并提供了一系列的优化策略和工具,以提高训练效率和性能。:适合模型大,数据少,需要对模型做切分,将模型参数划分为多个部分,放到不同的GPU上...
分布式深度学习之数据并行和模型并行
标签: 泛化
转载 在深度学习这一领域经常涉及到模型的**分布式**训练(**包括一机多GPU的...如果去查阅与分布式深度学习相关的资料,一般会看到两个词,模型并行和数据并行。 模型并行是指把模型的不同部分放置在各个设备上,这样
深度学习进行分布式训练(模型并行和数据并行优缺点):https://blog.csdn.net/qq_29462849/article/details/81185126
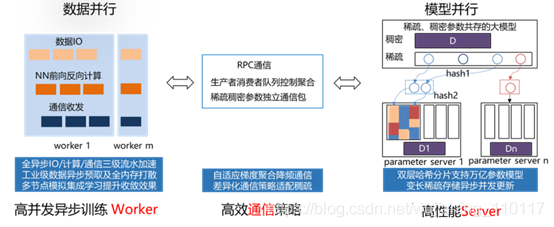
ZeRO-Infinity: Breaking the ...层间模型并行则是对模型层进行切分,业界也有很多做框架的公司管它叫Pipeline并行,但是我的观点是层间模型并行只有真的流水起来了才能够叫Pipeline并行。典型例子就是1D的Megatron。
数据并行 由于训练数据集太大,而无法一次将其全部载入内存。因此将数据集分为N份,分别装载到N个GPU节点中去进行梯度求导,然后将所有节点的求导结果进行加权平均,再sync update给所有节点(对于每个节点来说,...
<div class="htmledit_views"> 在深度学习这一领域经常涉及到模型的分布式训练(包括...
数据集分为n块,每块随机分配到m个设备(worker)中,相当于m个batch并行训练n/m轮,模型也被复制为n块,每块模型均在每块数据上进行训练,各自完成前向和后向的计算得到梯度,更新后,再传回各个worker。以确保每个...
数据并行 Data Parallelism 每块GPU上都有完整的模型(每个GPU上的模型参数是一样的)。将原来的训练数据切分为多份,分别投喂到每个GPU上的模型。每个GPU并行运行,随后进行模型的梯度汇总更新以及不同GPU的通信/...
此文翻译自[1],[1]对数据并行和模型并行进行了很好地区分,因此这里推荐给大家。 介绍 现在深度学习模型的参数量已经变得越来越多了,数据集的尺寸也随之疯狂地增长。为了在一个巨大的数据集上训练一个复杂的深度...
目前,数据并行和模型并行作为两种在深度神经网络中常用的并行方式,分别针对不同的适用场景,有时也可将两种并行混合使用。本文对数据并行和模型并行两种在深度神经网络中常用的并行方式原理及其通信容量的计算方法...

#资源达人分享计划#
介绍了微软Deepspeed大模型训练并行框架
通过研究基于PRAM (Parallel Random Access Machine)下的3种最大值查找并行算法中的不足,提出了一种比平衡树算法,快速查找法,双对数深度树方法并行成本(cost)更优的基于数据划分方法的最大值查找并行算法....
飞行器大数据量CAD模型并行预处理.pdf

#资源达人分享计划#
在本文中,我们将深入探讨PyTorch的数据并行与模型并行,揭示它们的核心概念、算法原理、最佳实践以及实际应用场景。 1. 背景介绍 深度学习模型的训练和推理过程中,计算资源和时间往往成为瓶颈。为了解决这个问题...
欢迎转载,转载请注明:本文出自Bin的专栏blog....Jeff Dean 在演讲中提到,当前的做法是:解决方案 = 机器学习(算法)+ 数据 + 计算力未来有没有可能变为:解决方案 = 数据 + 100 倍的计算力?由此可见,谷歌似乎...
最近语言大模型(LLM)异常火爆,一个非常特别的开源社区正在探索在消费级硬件上微调、提供服务和进行推理的最佳方式。为满足上述需求,出现了许多出色的开源代码库,以HuggingFace生态系统为中心,这些代码库还包括...
1.背景介绍 在深度学习领域,多GPU训练是一种重要的技术,可以显著提高训练速度和性能...深度学习模型的训练通常需要大量的计算资源,尤其是在处理大规模数据集或高精度模型时。单GPU训练可能无法满足这些需求,因...
推荐文章
- 【Java进阶】线程池之无限队列 - 使用工厂类Executors.newFixedThreadPool(n) ,创建无限队列线程池_线程池无限队列-程序员宅基地
- python 之路,致那些年,我们依然没搞明白的编码-程序员宅基地
- 国二报C语言,国二C语言.doc-程序员宅基地
- FTP快速搭建-程序员宅基地
- [原创]我的WCF之旅(7):面向服务架构(SOA)和面向对象编程(OOP)的结合——如何实现Service Contract的继承_servicecontract using-程序员宅基地
- openmediavault(OMV) (18)云相册(2)photoprism-程序员宅基地
- VS2017使用protobuf动态链接库的编译错误问题_vs2017运行不了protobuf项目-程序员宅基地
- idea右键项目没有出现git选项、idea工具栏没有Git快捷图标_idea 右键没有git-程序员宅基地
- m3u8索引文件介绍_69嗉媂x.m3u8-程序员宅基地
- 2021 泰迪杯 A 题_第十二届泰迪杯数据挖掘竞赛a题论文-程序员宅基地