HTMLParser 也是一款非常高效的 HTML 解析器,其支持 CSS 选择器提取 HTML中的节点。HTMLParser 的版本已不再更新,但并不影响其使用。
”爬虫解析html“ 的搜索结果
给定 HTML 字符串,可以使用 org.jsoup.Jsoup 类中的 parse(String html)方法,将 String 类型的 HTML 文件...而 JsoupXpath 则是在 Jsoup 的基础上扩展的支持 Xpath 语法的 HTML 文件解析器。示例,依旧解析课程URL。
HtmlAgilityPack 是 .NET 下的一个 HTML 解析类库。支持用 XPath 来解析 HTML 。 命名空间: HtmlAgilityPack
Python 爬虫的解析方式是将从网页获取到的 HTML 内容转化为程序可读取和处理的数据。常见的解析方式有正则表达式解析、CSS 选择器解析和 XPath 节点提取解析。

搜索热词Golang如何解析HTML代码用Golang的朋友都知道如果我们...由于我之前在写Pyhon的爬虫的时候也需要解析HTML标签;所以用过PyQuery和BS4.这次在用Golang写爬虫的时候就留意了一下是否有Golang版本的Query。git...

一个多线程爬虫解析html标题、链接、内容并将它们存储到hdfs 用法 首先,编译MutiThreadCrawler.java ,得到输出jar文件,然后输入 $ hadoop jar Crawler-0.1.jar ...
主要介绍了Python HTML解析器BeautifulSoup用法,结合实例形式详细分析了第三方库BeautifulSoup实现的爬虫解析器功能具体操作技巧,需要的朋友可以参考下
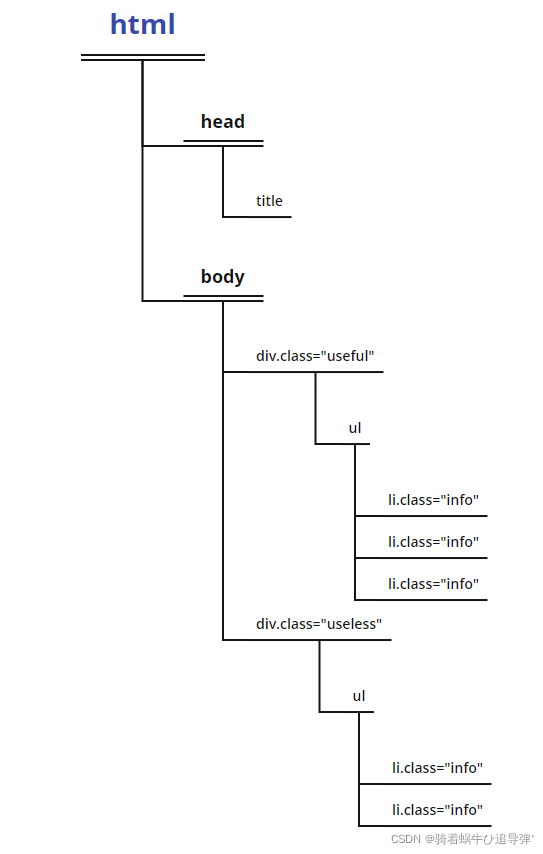

解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
Java爬虫+html网页解析 1、springboot项目,引入jsoup <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version>...
解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
包含html页面解析的网络爬虫程序C#实现,可以将html生成树形结构,添加代码后可提取相应内容存储到数据库中,实现数据的爬取。
我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行解析,按照自己的想法提取出想要的数据,所以今天我们主要来讲四种在Python中解析网页...
解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
爬虫之解析数据的4种方式:XPath解析数据、BeautifulSoup解析数据、正则表达式、pyquery解析数据。
java实现解析html网页爬虫
标签: 爬虫
java实现html静态页面爬虫
前言:本人很菜,学习很泛。 个人博客文章原地址,阅读更加美观 由于参加数学建模的需要,在这个寒假期间小学了一下爬虫(Python学习),想...其中最重要的应该是解析数据这部分,因为这部分html来编写对应的代码,从而
主要介绍了Python HTML解析模块HTMLParser用法,结合实例形式分析了HTMLParser模块功能、常用函数及作为爬虫工具相关使用技巧,需要的朋友可以参考下

在使用爬虫过程中可以用XPath来爬取网页中想要的数据。Xpath使用简洁的路径表达式来匹配XML/HTML文档中的节点或者节点集,通过定位网页中的节点,从而找到我们需要的数据。Xpath提供了100多个内建函数,包括了处理...
解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
我,菜鸡,有什么错误,还望...【python】爬虫篇:python连接postgresql(一):https://blog.csdn.net/lsr40/article/details/83311860 本文主要介绍了python通过bs4(BeautifulSoup)和xpath两种方法来获取爬到的...
主要介绍了Python爬虫工具requests-html使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下

解析内容: 爬虫对获取的HTML进行解析,提取有用的信息。常用的解析工具有正则表达式、XPath、Beautiful Soup等。这些工具帮助爬虫定位和提取目标数据,如文本、图片、链接等。 数据存储: 爬虫将提取的数据存储到...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地