关于RNN的理论部分我们已经在前面介绍过,所以这里直接上代码 数据是csv格式,只有两列,第一列是标签(但是为中文),第二列是text,文本内容。 当然这里也可以加入停用词我们需要构建和处理文本数据的词汇表。...
”芬威克树“ 的搜索结果
周围有一些数据结构非常有用,但大多数程序员都不知道。 他们是哪一个? 每个人都知道链接列表,二叉树和哈希,但是例如跳过列表和布隆过滤器 。 我想知道更多不常见的数据结构,但值得了解,因为
雪花一点红2021-05-22 12:53:44点灭只看此人举报全场这么多失误 其实就很简单 套路被摸透了全场这么多失误 其实就很简单 套路被摸透了亮了(1677)回复查看评论(38)冠军射手沙美特2021-05-22 12:49:04点灭只看此人举报...
"疮": "chuāng","窗": "chuāng","幢": "zhuàng","床": "chuáng","闯": "chuǎng","创": "chuàng","霜": "shuāng","双": "shuāng","桩": "zhuāng","庄": "zhuāng","装": "zhuāng","妆": "zhuāng","撞": ...
T1 Mas的仙人掌:考虑1=[路径上点的个数-路径上边的个数],树链剖分后变成区间赋值,注意要考虑0的情况,要把运算struct起来。 T2 Z的礼物 :用b表示a,斯特林反演一下,用a表示b,倍增求出多项式即可。 T3 Mas和Z玩...
工作中需要将繁体中文转换成简体中文 上网找了些资料,发现这个包最方便 安装方法 不需要什么安装方法,只需要把这两个文件下载下来,保存到与代码同一目录下即可 ...https://raw.githubusercontent.com/skydark/nst...
链表 一个链表是数据元素的线性集合, 元素的线性顺序不是由它们在内存中的物理位置给出的。 相反, 每个元素指向下一个元素。它是由一组节点组成的数据结构,这些节点一起,表示序列。 双向链表 一个 双向链表(doubly ...
国赛、美赛各种整理后的资料(有偿提供,替朋友转载,扫描下方二维码提问,或者向博主扫描提问即可获得,2元/份) 数学专业词汇 A absolute value 绝对值 accept 接受 acceptable region 接受域 ...
继续字符编码的学习。今天介绍一下GBK(汉字内码扩展规范),GB 2312 GB18030。引用网友的话可以概括一下: GBK和UTF8的区别:GBK就是在保存你的帖子的时候,一个汉字占用两个字节。。外国人看会出现乱码,此为我中华...
UTF,是UnicodeTransformation Format的缩写,意为Unicode转换格式。UTF-8是UNICODE的一种变长字符编码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。...
Unicode汉字编码表1 Unicode编码表 Unicode只有一个字符集,中、日、韩的三种文字占用了Unicode中0x3000到0x9FFF的部分 Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符, 比如汉字”经”的编码是0x7ECF...
构思小说的时候感觉名字不太好取,所以我自己实现了一个随机取名器,虽然有那种随机生成名字的网站,不过我想着 一是写代码锻炼一下自己,二是万一以后有什么特殊需求,可以根据自己的需要来改。
【代码】含编程常见英语翻译带音标。
这个很重要,如何修改我就不多赘述,可以自行搜索如何修改。LVGL自带CJK字体库,包含了一小部分中文字体,以繁体字为主,如果包含了需要的汉字,那就可以直接用。首先打开lv_conf.h文件,具体位置就在根目录。...
今天做测试数据用到了记录下 汉字清单 乙, 一, 乃, 丁, 卜, 刀, 九, 了, 七, 八, 厂, 儿, 二, 几, 力, 人, 入, 十, 又, 久, 丸, 丈, 乞, 乡, 勺, 刃, 亏, 凡, 卫, 亿, 亡, 叉, 川, 寸, 弓, 巾, 女, 尸, 士, 夕, 么, ...
选择文件上传,等待处理,下载,使用。附常用汉字,字体文件请善用百度。环境:python3。
注意:下面这两段是代理区。即第1——16平面的间接表示,四个字节的汉字就在这里表示 D800-DBFF:High-half zone of UTF-16 DC00-DFFF:Low-half zone of UTF-16 本篇中包含了所有常用汉字27973个,剩余汉字使用...
下列汉字取自国标(GB 2312-80)中的分级与排列内容;包含所有的第一级汉字和第二级汉字中的常用部分。第一级汉字(16—55区的汉字)以拼音字母为序进行排列,同音字以笔形顺序横、竖、撇、捺、折为序,起笔相同的按第...
理论计算机科学电子笔记193(2007)3-18www.elsevier.com/locate/entcs新话中的可执行语法GiladBrachaCadence DesignSystems美国摘要我们描述了一个解析器组合子库的设计和实现在新语,一个新的语言在Smalltalk家庭...
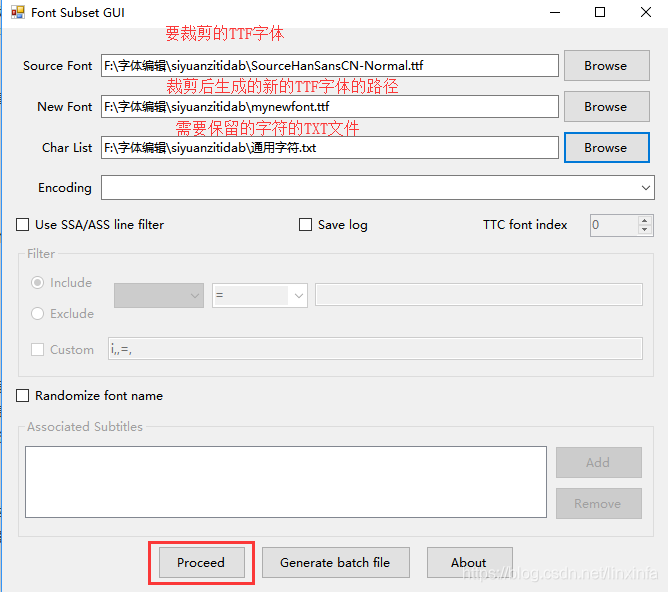
使用字蛛font-spider,压缩文字font.ttf文字的步骤。
工程6(2020)20研究动物疾病研究综述疾病控制、预防和农场生物安全:兽医流行病学的作用Ian D.罗伯逊a,baMurdoch大学兽医与生命科学学院兽医学院,Perth,WA 6150,Australiab阿提奇莱因福奥文章历史记录:2018年8...
中文汉字拼音(常用3729字)
文章人类X染色体的异常选择与古杂合子图形摘要亮点D 在X染色体的多样性大幅减少非-非洲人积极选择在非非洲人群中传播长单倍型d选择的单倍型来自没有尼安德特人混合物[4]一个古老的男性基因组将这些选择性扫描追溯到...
GB2312简体中文编码表
标签: 算法
GB2312简体中文编码表 code +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F A1A0 、 。 · ˉ ˇ ¨ 〃 々 — ~ ‖ … ‘ ’ A1B0 “ ” 〔 〕 〈 〉 《 》 「 」 『 』 〖 〗 【 】 A1C0 ± × ÷ ∶ ∧ ∨ ∑ ...
支持dotnet core的汉字转拼音,而且支持多音字。
正则表达式高阶(四)
标签: 正则表达式
正则不常用的方式之使用正则匹配汉字
模型推理输出文本区域需要经过二值化之后使用 opencv 查找轮廓,然后获取最小外接矩形并扩展得到最终的文本区域,后续需要矩形旋转、投影变换等操作作为文本识别的输入。文本识别可以用crnn等各种模型。
Domino M-Series 系列 设置说明
用java随机生成中文名字(百家姓/常用名/随机生成汉字)
推荐文章
- 记录CentOS7 Linux下安装MySQL8_适合正式环境_干货满满(超详细,默认开启了开机自启动,设置表名忽略大小写,提供详细配置,创建非root专属远程连接用户)_centos7安装mysql8-程序员宅基地
- python 读取grib \grib2-程序员宅基地
- Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!-程序员宅基地
- Datawhale-集成学习-学习笔记Day4-Adaboost-程序员宅基地
- TexStudio配置以及解决无法Build&View_texstudio 无法启动 build & view:pdflatex:"d:/data/texl-程序员宅基地
- 用户空间访问I2C设备驱动-程序员宅基地
- 人脸识别算法初次了解-程序员宅基地
- maven的pom文件学习-程序员宅基地
- wamp mysql 没有启动,WAMP中mysql服务突然无法启动 解决方法-程序员宅基地
- 《树莓派Python编程入门与实战(第2版)》——3.7 创建Python脚本-程序员宅基地