
”词频统计“ 的搜索结果
操作:strip_html(cls, text) 去除html标签separate_words(cls, text, min_lenth=3) 文本提取get_words_frequency(cls, words_list) 获取词频源码:class docprocess(object):@classmethoddef strip_htm...
c语言顺序表单词词频统计 先用结构体来记录单词和单词的词频 struct word { char w[Word_Max]; int count; }a[1000]; 其中a[1000]为我们记录的顺序表 while (fscanf(fp, "%s", words) != EOF) { deleteNotA...
做一个词频统计程序,该程序具有以下功能 基本要求:(1)可导入任意英文文本文件(2)统计该英文文件中单词数和各单词出现的频率(次数),并能将单词按字典顺序输出。(3)将单词及频率写入文件。#include #...
给定一个string数组article及其大小n及一个待统计单词word,请返回该单词在数组中出现的频数。文章的词数在1000以内 解题思路 (1)暴力法 用一个int变量count统计单词word出现的次数,遍历所有的article元素,与...

Hadoop实现词频统计(按照词频降序排列以及相同词频的单词按照字母序排列) 分为两步词频统计和排序。第一个map reduce与过滤停用词的代码相同;第二个map reduce中的map将键值对内容交换,map到reduce的shufle中会...


主要是读取文本,然后进行分词、词干提取、去停用词、计算词频,有界面,很实用亲测可用, 谢谢支持。
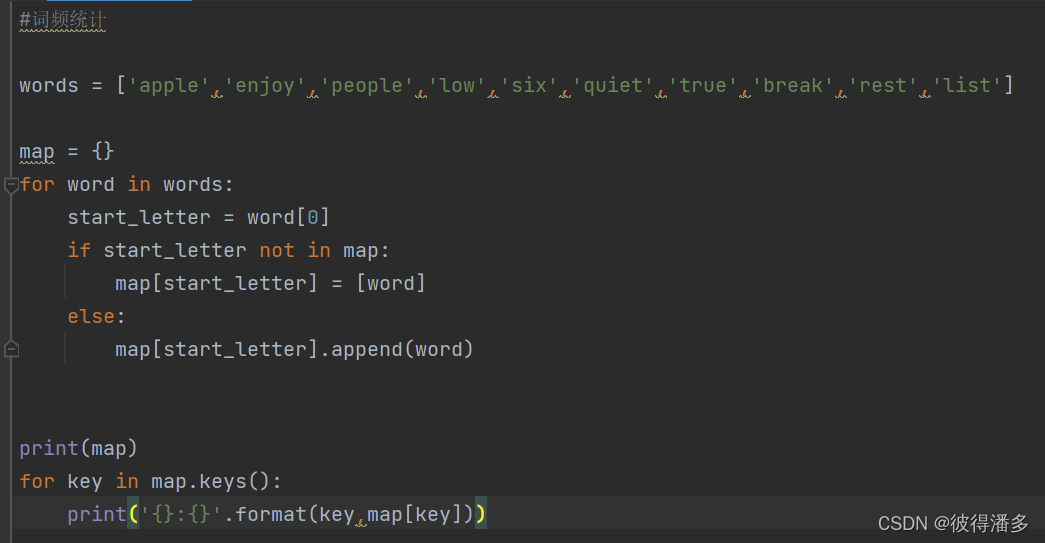
cipin.cpp_词频统计_
标签: 词频统计
从给的文件中读取内容,在控制台统计词频。
在本文中利用Python对Hamlet英文词频进行统计,我们解决该问题的基本流程应该如下:1、读取文件2、将所有英文字母变成小写3、根据标点符号,对!'#$%&()*+,-./:;?@[\\]^_‘{|}~等对单词进行分割,形成列表4、对每个...
数据名称:上市公司制造业-智能制造词频统计 数据样本:2001-2021年 数据 样本:28631条 原始来源:上市公司年报 参考文献 参考文献:郭磊,贺芳兵,李 静雯.中国智能制造发展态势分析——基于制造业上市公司年报的...
Python开发的小工具:验证码识别+词频统计+LBP人脸识别+免费代理IP+抓包工具嗅探器+文本分类+源码,适合毕业设计、课程设计、项目开发。项目源码已经过严格测试,可以放心参考并在此基础上延申使用~ Python开发的小...


这里写目录标题一、词频统计:1.基本概念及原理2.词频统计方法二、词云1.词云绘制工具:2.python词云绘制——Wordcloud三、基于分词频数绘制词云1.利用词频绘制词云2.美化词云 一、词频统计: 1.基本概念及原理 ...
中文词频统计1. 下载一长篇中文小说。《倚天屠龙记》2. 从文件读取待分析文本。3. 安装并使用jieba进行中文分词。pip install jiebaimport jiebaljieba.lcut(text)4. 更新词库,加入所分析对象的专业词汇。jieba.add...
字典树实现词频统计 Trie树(字典树) 字典树又叫前缀树,是处理字符串常用的数据结构,最近和朋友一起粗略写了一下关于字典树的词频统计。 一、功能介绍 文件流读写单词; 将读到的单词插入树中; 打印树,打印出...
python使用jieba分词,词频统计,基本使用
实例10:文本词频统计 引用文本 英文文本:Hamet https://python123.io/resources/pye/hamlet.txt 中文文本:《三国演义》 https://python123.io/resources/pye/threekingdoms.txt
总体的步骤为读入文本,大小写转换,特殊字符转换,分词,词频统计,排序。通过观察词语频率最高的几个词,我们大致可以了解该文章的主要内容。这一小节,我们没有涉及到英文文章中去停用词的操作。 停用词:出现的...


Hadoop的词频统计源代码WordCount
一.环境以及注意事项1.windows10家庭版 python 3.7.12.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示请安装到C:\Windows\Fonts 里面5....词频统计以及输出(1) 代码如下(封装为tx...

词频统计.py
推荐文章
- 用好ASP.NET 2.0的URL映射-程序员宅基地
- C语言等级考试是把题目删了,历年全国计算机的等级考试二级C语言上机考试地训练题目库及答案详解(72页)-原创力文档...-程序员宅基地
- Microsoft Office显示正在更新无法打开的问题_正在更新microsoft 365和office-程序员宅基地
- 非常好的Ansible入门教程(超简单)-程序员宅基地
- 【Gradle-8】Gradle插件开发指南-程序员宅基地
- 使用PL/SQL Developer软件解锁_plsqldev表格锁怎么打开-程序员宅基地
- 【Windows Server 2019】Web服务 IIS 配置与管理——配置 IIS 进阶版 Ⅳ_iis默认路径-程序员宅基地
- 网络中的各层协议_发送消息时各层协议-程序员宅基地
- UCRT: VC 2015 Universal CRT, by Microsoft_vc15rt-程序员宅基地
- 关于EntityFramework 7 开发学习_entiry framework 7 书籍-程序员宅基地