二叉树(Java实现)_java二叉树-程序员宅基地
声明:本文部分文章取自于
Java中关于二叉树详解_来学习的小张的博客-程序员宅基地_java 二叉树原理
更多关于二叉树详情可以点击上面链接
目录
一:树形结构
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 有一个特殊的节点,称为根节点,根节点没有前驱节点;
- 除根节点外,其余节点被分成
M(M > 0)个互不相交的集合T1、T2、......、Tm,其中每一个集合Ti (1 <= i<= m)又是一棵与树类似的子树。每棵子树的根节点有且只有一个前驱,可以有0个或多个后继;- 树是递归定义的。
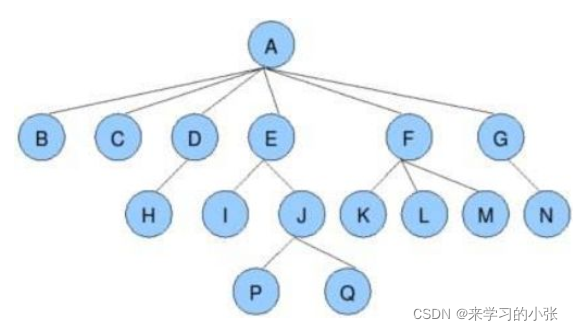
- 节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:
A的度为6;- 树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为
6;- 叶子节点或终端节点:度为
0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点;- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点;
- 根结点:一棵树中,没有双亲结点的结点;如上图:A
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
以下概念仅做了解即可:
- 非终端节点或分支节点:度不为0的节点; 如上图:
D、E、F、G...等节点为分支节点;- 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:
B、C是兄弟节点;- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:
H、I互为兄弟节点;- 节点的祖先:从根到该节点所经分支上的所有节点;如上图:
A是所有节点的祖先;- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙;
- 森林:由
m(m>=0)棵互不相交的树的集合称为森林。
二:二叉树
2.1 二叉树的遍历:
使用前序、中序、后续来遍历二叉树
- 前序遍历:先输出父节点,再遍历左子树和右子树
- 中序遍历:先遍历左子树,再输出父节点,再遍历右子树
- 后序遍历:先遍历左子树,再遍历右子树,最后输出父节点
小结:看输出父节点的顺序,就确定是前序、中序还是后序。
分析二叉树的前序,中序,后序的遍历步骤:
1.创建一颗二叉树
2.前序遍历
- 2.1先输出当前节点(初始的时候是root节点)
- 2.2如果左子节点不为空,则递归继续前序遍历
- 2.3如果右子节点不为空,则递归继续前序遍历
3.中序遍历
- 3.1如果当前节点的左子节点不为空,则递归中序遍历
- 3.2输出当前节点
- 3.3如果当前的右子节点不为空,则递归中序遍历
4.后序遍历
- 4.1如果当前节点的左子节点不为空,则递归后序遍历
- 4.2如果当前节点的右子节点不为空,则递归后序遍历
- 4.3输出当前节点
5.前、中、后序遍历代码实现:
public class BinaryTreeDemo {
public static void main(String[] args) {
//先需要创建一颗二叉树
BinaryTree binaryTree=new BinaryTree();
//创建需要的结点
HeroNode root=new HeroNode(1,"宋江");
HeroNode node2=new HeroNode(2,"吴用");
HeroNode node3=new HeroNode(3,"卢俊义");
HeroNode node4=new HeroNode(4,"林冲");
HeroNode node5=new HeroNode(5,"武松");
HeroNode node6=new HeroNode(6,"鲁智深");
HeroNode node7=new HeroNode(7,"杨志");
//说明,我们先手动创建该二叉树,后面我们学习递归的方式创建而常数
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
node3.setRight(node7);
binaryTree.setRoot(root);
//测试:
System.out.println("前序遍历");//1,2,4,5,3,6,7
binaryTree.preOrder();
System.out.println("中序遍历");//4,2,5,1,6,3,7
binaryTree.infixOrder();
System.out.println("后序遍历");//4,5,2,6,7,3,1
binaryTree.postOrder();
}
}
//定义二叉树
class BinaryTree{
private HeroNode root;//根节点
public void setRoot(HeroNode root){
this.root=root;
}
//前序遍历
public void preOrder(){
if(this.root!=null){
this.root.preOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void infixOrder(){
if(this.root!=null){
this.root.infixOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
//后序遍历
public void postOrder(){
if(this.root!=null){
this.root.postOrder();
}else {
System.out.println("二叉树为空,无法遍历");
}
}
}
//先创建HeroNode结点
class HeroNode{
private int no;
private String name;
private HeroNode left;//默认为null
private HeroNode right;//默认为null
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
//编写前序遍历的方法
public void preOrder(){
System.out.println(this);//先输出父结点(谁调用这个方法,谁就是this)
//递归向左子树前序遍历
if(this.left!=null){
this.left.preOrder();
}
//递归向右子树前序遍历
if(this.right!=null){
this.right.preOrder();
}
}
//编写中序遍历的方法
public void infixOrder(){
//递归向左子树中序遍历
if(this.left!=null){
this.left.infixOrder();
}
//输出父结点
System.out.println(this);
//递归向右子树中序遍历
if(this.right!=null){
this.right.infixOrder();
}
}
//编写后序遍历的方法
public void postOrder(){
//递归向左子树后序遍历
if(this.left!=null){
this.left.postOrder();
}
//递归向右子树后序遍历
if(this.right!=null){
this.right.postOrder();
}
//输出父结点
System.out.println(this);
}
}2.2 二叉树的查找:
目的:使用前序、中序、后序的方式来查询指定的节点。
前序查找思路:
- 先判断当前节点的no是否等于要查找的
- 如果是相等的,则返回当前节点
- 如果不相等,则判断当前节点的左子节点是否为空,如果不为空,则递归前序查找
- 如果左递归前序查找,找到节点,则返回,否则继续判断,当前的节点的右子节点是否为空,如果不为空,则继续向右递归前序查找
中序查找思路:
- 判断当前节点的左子节点是否为空,如果不为空,则递归中序查找
- 如果找到,则返回,如果没有找到,就和当前节点比较,如果是则返回当前节点,否则继续进行右递归的中序查找
- 如果右递归中序查找,找到就返回,否则为null
后序查找思路:
- 判断当前节点的左子节点是否为空,如果不为空,则递归后序查找
- 如果找到,就返回,如果没有找到,就判断当前节点的右子节点是否为空,如果不为空,则右递归进行后序查找,如果找到,就返回
- 就和当前节点进行,如果找到则返回,否则返回null
查找指定节点的部分代码实现:
//编写前序查找的方法
public HeroNode preSearch(int no){
//先判断当前节点是否符合
if(this.no==no){
return this;
}
HeroNode resNode=null;
//向左递归
if(this.left!=null){
resNode=this.left.preSearch(no);
}
//向右递归(判断左递归得到的节点是否为空,如果为空,则进行右递归)
if(resNode==null&&this.right!=null){
resNode=this.right.preSearch(no);
}
return resNode;//如果最终还是没有找到,则返回null
}
//编写中序查找的方法
public HeroNode infixSearch(int no){
HeroNode resNode=null;
if(this.left!=null){
resNode=this.left.infixSearch(no);
}
if(this.no==no){
return this;
}
if(this.right!=null&&resNode==null){//左边没有找到,找右边
resNode=this.right.infixSearch(no);
}
return resNode;//不管有没有找到,都返回resNode
}
//编写后序查找的方法
public HeroNode postSearch(int no){
HeroNode resNode=null;
if(this.left!=null){
resNode=this.left.postSearch(no);
}
if(this.right!=null&&resNode==null){
resNode=this.right.postSearch(no);
}
if(this.no==no){
return this;
}
return resNode;
}2.3 二叉树删除节点:(简单版)
规定:如果要删除的节点是叶子节点,则直接删除,如果是非叶子节点,则删除该子树。
思路:
首先先处理:
考虑如果树是空树root,如果只有一个root节点,则等价将二叉树置空。
如果不是,则进行下面步骤:
- 因为我们的二叉树是单向的,所以我们是判断当前节点的子节点是否需要删除节点,而不能去判断当前这个节点是不是需要删除节点。
- 如果当前节点的左子节点不为空,并且左子节点就是要删除节点,就将this.left=null;并且就返回(结束递归删除)
- 如果当前节点的右子节点不为空,并且右子节点就是要删除节点,就将this.right=null,并且就返回(结束递归删除)
- 如果第2和第3步没有删除节点,那么我们就需要向左子树进行递归删除。
- 如果第4步也没有删除节点,则应当向右子树进行递归删除。
节点删除的代码实现:
//二叉树部分:删除节点
public void deleteNode(int no){
if(root!=null){
//如果只有一个root节点,这里立即判断root是不是要删除节点
if(root.getNo()==no){
root=null;
}else {
//递归删除
root.deleteNode(no);
}
}else {
System.out.println("二叉树为空,删除失败");
}
}
//链表部分:
//递归删除节点
public void deleteNode(int no){
//判断当前节点的左子节点
if(this.left!=null&&this.left.no==no){
this.left=null;
return;
}
//判断当前节点的右子节点
if(this.right!=null&&this.right.no==no){
this.right=null;
return;
}
//左子树递归删除
if(this.left!=null){
this.left.deleteNode(no);
}
//右子树递归删除
if(this.right!=null){
this.right.deleteNode(no);
}
}2.4 顺序存储二叉树:
基本说明:从数据存储来啊看,数组存储方式和树的存储方式可以相互转化,即数组可以转换成树,也可以转换成数组。
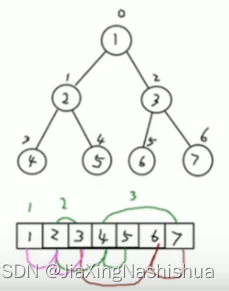
要求:
(1)图中的二叉树的节点,要求以数组的方式来存放arr【1,2,3,4,5,6,7】
(2)要求在遍历数组arr时,仍然可以以前序遍历、中序遍历和后序遍历的范围广是完成节点的遍历。
思路:
- 顺序二叉树通常只考虑完全二叉树。
- 数组下标为n的元素所对应的左子节点所在的下标为(2*n+1);
- 数组下标为n的元素所对应的右子节点所在的下标为(2*n+2);
- 数组下标为n的元素所对应的父节点为(n-1)/2;
提示:(可以自己对着上图验证一下)
顺序存储二叉树的代码实现:
public class ArrayBinaryTreeDemo {
public static void main(String[] args) {
int[] arr={1,2,3,4,5,6,7};
ArrayBinaryTree arrayBinaryTree = new ArrayBinaryTree(arr);
arrayBinaryTree.preOrder(); //1,2,4,5,3,6,7
}
}
//编写一个ArrayBinaryTree,实现顺序存储二叉树遍历
class ArrayBinaryTree{
private int[] arr;//存储数据节点的数组
public ArrayBinaryTree(int[] arr){
this.arr=arr;
}
//编写一个方法,完成顺序存储二叉树的前序遍历
//重载preOrder
public void preOrder(){
this.preOrder(0);
}
public void preOrder(int index){
//如果数组为空,或arr.length=0
if(arr==null || arr.length==0){
System.out.println("数组为空,不能按照二叉树的前序遍历");
}
//输出当前这个元素
System.out.println(arr[index]);
//向左递归遍历
if((index*2+1)<arr.length){
preOrder(2*index+1);
}
//向右递归遍历
if((index*2+2)<arr.length){
preOrder(2*index+2);
}
}
}2.5 线索化二叉树:

问题分析:
- 当我们对上面的二叉树进行中序遍历时,数列为{8,3,10,1,6,14};
- 但是6,8,10,14这几个节点的左右指针,并没有完全的利用上
- 如果我们希望充分利用各个节点的左右指针,让各个节点可以指向自己的前后节点,怎么办?
- 解决方案:线索化二叉树
使用场景:
- 线索化的实质就是将二叉链表中的空指针改为指向前驱节点或后继节点的线索;
- 线索化的过程就是修改二叉链表中空指针的过程,可以按照前序、中序、后序的方式进行遍历,分别生成不同的线索二叉树;
- 有了线索二叉树之后,我们再次遍历时,就相当于操作一个双向链表。
- 使用场景:如果我们在使用二叉树过程中经常需要遍历二叉树或者查找节点的前驱节点和后继节点,可以考虑采用线索二叉树存储结构。
线索二叉树基本介绍:
- n个节点的二叉链表中含有(n+1)【公式:2n-(n-1)=n+1】个空指针域。利用二叉链表中的空指针域,存放指向该节点在某种遍历次序下的钱去和后继节点的指针(这种附加的指针称为“线索”)。
- 这种加上了线索的二叉链表称为线索链表,相应的二叉树称为线索二叉树(Thread BinartTree)。根据线索性质的不同,线索二叉树可分为前序线索二叉树、中序线索二叉树和后序线索二叉树三种。
- 一个节点的前一个节点,称为前驱节点。
- 一个节点的后一个节点,称为后继节点。
思路分析:
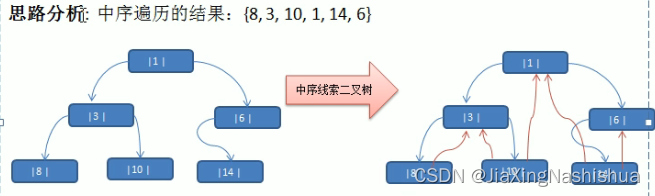
说明:当线索化二叉树后,Node节点的属性left和right,有如下情况:
(1)left指向的是左子树,也可能是指向的前驱节点,比如 1 节点left指向的左子树,而 10 节点的left指向的就是前驱节点。
(2)rigth指向的是右子树,也可能是指向后继节点,比如 1 节点right指向的是右子树,而 10 节点的right指向的是后继节点。
public class ThreadedBinaryTreeDemo {
/*
中序线索化二叉树
*/
public static void main(String[] args) {
HeroNode root=new HeroNode(1,"tom");
HeroNode node2=new HeroNode(3,"jack");
HeroNode node3=new HeroNode(6,"smith");
HeroNode node4=new HeroNode(8,"mary");
HeroNode node5=new HeroNode(10,"king");
HeroNode node6=new HeroNode(14,"dim");
//二叉树,后面我们要递归创建,现在简单处理使用手动创建
root.setLeft(node2);
root.setRight(node3);
node2.setLeft(node4);
node2.setRight(node5);
node3.setLeft(node6);
BinaryTree binaryTree = new BinaryTree();
binaryTree.setRoot(root);
binaryTree.threadedNodes();
//测试:
HeroNode leftNode = node5.getLeft();
HeroNode rightNode = node5.getRight();
System.out.println("10 节点的前驱节点:"+leftNode);
System.out.println("10 节点的后继节点:"+rightNode);
}
}
class BinaryTree{
private HeroNode root;//根节点
//为了实现线索化,需要创建要给指向当前节点的前驱节点的指针
//在递归进行线索化时,pre总是保留前一个节点
private HeroNode pre=null;
public void setRoot(HeroNode root){
this.root=root;
}
//重载threadedNodes方法
public void threadedNodes(){
this.threadedNodes(root);
}
//编写对二叉树进行中序线索化的方法
/**
*
* @param node:就是当前需要线索化的节点
*/
public void threadedNodes(HeroNode node){
//如果node==null,不能线索化
if(node==null){
return;
}
//(一)先线索化左子树
threadedNodes(node.getLeft());
//(二)线索化当前节点
//处理当前节点的前驱节点
//以8节点来理解
//8节点的.left=null,8节点的.leftType=1
if(node.getLeft()==null){
//让当前节点的左指针指向前驱节点
node.setLeft(pre);
//修改当前节点的左指针的类型,指向前驱节点
node.setLeftType(1);
}
//处理后继节点
if(pre!=null&&pre.getRight()==null){
//让前驱节点的右指针指向当前节点
pre.setRight(node);
//修改前驱节点的右指针类型
pre.setRightType(1);
}
//!!! 每处理一个节点后,让当前节点是下一个节点的前驱节点
pre=node;
//(三)再线索化右子树
threadedNodes(node.getRight());
}
}
//先创建HeroNode结点
class HeroNode{
private int no;
private String name;
private HeroNode left;//默认为null
private HeroNode right;//默认为null
//说明
//1.如果leftType==0表示指向的是左子树,1则表示指向前驱节点
//2.如果rightType==0表示指向是右子树,1则表示指向后继节点
private int leftType;
private int rightType;
public HeroNode(int no, String name) {
this.no = no;
this.name = name;
}
public int getLeftType() {
return leftType;
}
public void setLeftType(int leftType) {
this.leftType = leftType;
}
public int getRightType() {
return rightType;
}
public void setRightType(int rightType) {
this.rightType = rightType;
}
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public HeroNode getLeft() {
return left;
}
public void setLeft(HeroNode left) {
this.left = left;
}
public HeroNode getRight() {
return right;
}
public void setRight(HeroNode right) {
this.right = right;
}
@Override
public String toString() {
return "HeroNode [no=" + no + ", name=" + name + "]";
}
}遍历线索化二叉树:
说明:对前面的中序线索化的二叉树,进行遍历
分析:因为线索化后,各个节点指向有变化,因此原来的遍历方式不能使用,这是需要使用新的方式遍历线索化二叉树,各个节点开头通过线型方式遍历,因此无需使用递归方式,这样也提高了遍历的效率。遍历的次序应当和中序遍历保持一致。
代码实现:
//遍历线索化二叉树
public void threadedList(){
//定义一个变量,存储当前遍历的节点,从root开始
HeroNode node=root;
while(node!=null){
//循环的找到leftType==1的节点,第一个找到就是8节点
//后面随着遍历而变化,因为当leftType==1是,说明该节点按照线索化处理后的有效节点
while(node.getRightType()==0){
node=node.getLeft();
}
//打印当前这个节点
System.out.println(node);
//如果当前节点的右指针指向的是后继节点,就一直输出
while (node.getRightType()==1){
//获取到当前节点的后继节点
node=node.getRight();
System.out.println(node);
}
//替换这个遍历的节点
node=node.getRight();
}
}智能推荐
概念理解:面向对象编程(OOP)-程序员宅基地
文章浏览阅读49次。一、对象的综述面向对象编程(OOP)具有多方面的吸引力。对管理人员,它实现了更快和更廉价的开发与维护过程。对分析与设计人员,建模处理变得更加简单,能生成清晰、易于维护的设计方案。对程序员,对象模型显得如此高雅和浅显。此外,面向对象工具以及库的巨大威力使编程成为一项更使人愉悦的任务。每个人都可从中获益,至少表面如此。所有编程语言的最终目的都是解决企业又或者人在现实生活中所遇到的问题,最初我们..._咋样理解面向对象编程 -baijiahao
C语言之makefile简介及简单应用_c makefile-程序员宅基地
文章浏览阅读963次。其实makefile最大的优点就是提供了”自动编译”,只要内容编写好,一个make命令,整个工程就会自动编译程序,大大提高了软件开发的效率。 所以 会使用makfile还是一个很重要的技能哦!!!make工具最主要也是最基本的功能就是通过makefile文件来描述源程序之间的相互关系并自动维护编译工作。而makefile 文件需要按照某种语法进行编写,文件中需要说明如何编译各个源文件并连接生..._c makefile
数据库新增幂等操作_接口幂等性-程序员宅基地
文章浏览阅读417次。含义:接口可重复调用后,在调用方多次调用的情况下,接口最终得到的结果是一致的。有些接口天然具备幂等性,如查询接口。除查询外,增加、更新、删除都要保证幂等性。如何保证幂等性?1.全局唯一ID(防止新增脏数据)如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作前先根据这个全局唯一ID是否存在来判断这个操作是否已经执行,如果不存在则把全局唯一ID存储到存储系统中,比如数据库,re..._如何保证数据库增加的幂等
java为什么要学习数组_为什么数组要从零开始?-程序员宅基地
文章浏览阅读354次。如题,数组第一个元素为什么要从零开始,而不从一开始?感觉这很反人类呀,正常来讲,一个集合的开始,不应该从一吗?对于这个问题,我觉得可以从以下两方面来考虑。设计层面我们先了解一下数组最基本的结构和寻址方式(即实现方式)。现在市面上无论是C、Java、PHP,还是Go或者其他编程语言,他们数组的实现方式,应该都是一样的:一段连续的内存。数组在分配内存的时候,我们会知道数组的开始地址(PS:在目前下标为..._java 为什么使用数组
魔兽世界plus怎么收费/怎么充值 手把手教你充值-程序员宅基地
文章浏览阅读295次,点赞8次,收藏4次。魔兽世界plus怎么收费/怎么充值 手把手教你充值。魔兽世界plus怎么收费/怎么充值 手把手教你充值。,也就是我们玩家要需要。
表格内容的展开和折叠效果《超实用的JavaScript代码段》笔记_html设置table展开怎么设置-程序员宅基地
文章浏览阅读902次。<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>表格内容的展开和折._html设置table展开怎么设置
随便推点
Windows下安装Hive(包安装成功)_windows安装hive-程序员宅基地
文章浏览阅读5.1k次,点赞12次,收藏28次。Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名。可以发现,自动连接MySQL去创建schema hive,并执行脚本。可以通过访问namenode和HDFS的Web UI界面(以及resourcemanager的页面(先在Hive安装目录下建立。根据自己的Hive安装路径(根据自己的Hive安装路径(请严格按照版本来安装。在Hadoop管理台(_windows安装hive
无偏估计+求样本的方差为何除n-1_设总体x~n(θ,1),gθ=θ2,试求gθ的无偏估计的方差下界-程序员宅基地
文章浏览阅读464次。$$f(x)={xˉ=∑1nxin均值S2=∑1n(x−xi)2n−1方差f(x)=\begin{cases} \bar{x}=\frac{ \sum_{1}^{n} x_{i} }{n}& \text{均值}\\S^2= \frac{ \sum_{1}^{n} (x- x_{i} )^2 }{n-1} & \text{方差}\end{cases}f(x)={xˉ=n∑1nxiS2=n−1∑1n(x−xi)2均值方差求样本方差为什么除n−1?求样本方差_设总体x~n(θ,1),gθ=θ2,试求gθ的无偏估计的方差下界
Linux学习教程,Linux入门教程(超详细)| 网址推荐_linux中大量使用脚本语言,而不是c语言!-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏51次。1Linux简介2Linux安装3Linux文件和目录管理4Linux打包(归档)和压缩5Vim文本编辑器6Linux文本处理(Linux三剑客)7Linux软件安装8Linux用户和用户组管理9Linux权限管理10Linux文件系统管理11Linux高级文件系统管理12Linux系统管理13Linux备份与恢复14Linux系统服务管理15Linux系统日志管理16Linux启动管理17LAMP环境搭建和LNMP环境搭建18SEL..._linux中大量使用脚本语言,而不是c语言!
c语言函数base,c中base的用法-程序员宅基地
文章浏览阅读1.7k次。c中base的用法的用法你知道吗?下面小编就跟你们详细介绍下c中base的用法的用法,希望对你们有用。c中base的用法的用法如下:1、调用基类中的重名方法[csharp]public class Person{protected string ssn = "444-55-6666";protected string name = "John L. Malgraine";public virtua..._c语言中base=16是什么意思
为什么接口中变量要用final修饰_接口参数都定义为final的作用-程序员宅基地
文章浏览阅读6.7k次,点赞3次,收藏7次。今天碰到这个问题时候,还真不好理解,只知道interface中的变量默认是被public static final 修饰的,接口中的方法是被public和abstrct修饰的。查阅了很多资料,做了些例子,得出以下结论,不足的地方希望大家指出。 Java代码 /* * 关于抽象类和接口 * * 1_接口参数都定义为final的作用
【R语言学习笔记】6、List列表详解_r语言怎么查看list有几个项目-程序员宅基地
文章浏览阅读4.4k次,点赞3次,收藏25次。创建一个list列表> mylist <- list(stud.id = 1234,+ stud.name = "Tom",+ stud.marks = c(12, 3, 14, 25, 19))> mylist$stud.id[1] 1234$stud.name[1] "Tom"$stud.marks[1] 12 3 14 25 19取列表的值注..._r语言怎么查看list有几个项目