C语言再学习 -- 编程规范_c语言编程规范-程序员宅基地
C语言编程规范这部分一直想总结一下。现在终于付诸行动了。
其实之前讲过一些面试题,参看:嵌入式面试知识点总结 – C语言篇
里面已经有包含一部分了,比如《高质量C++ C编程指南》.林锐着.pdf。
此次主要参考 华为技术有限公司c语言编程规范 和 MISRA C2012 再详细讲一下C语言的编程规范。
下载:编程规范

这篇文章主要以MISRA C 2012 中文版为基础,再将华为C语言编程规范融入其中。
看来之前总结两年的 C语言再学习 专栏,又有用武之地了。
一、名词解释
1、声明(declare)和定义(define)
参看:C语言再学习 – 声明与定义
声明一个变量只是将变量名标识符的有关信息告诉编译器,使编译器“认识”该标识符,但声明不一定引起内存的分配。而定义变量意味着给变量分配内存空间,用于存放对应类型的数据,变量名就是对相应的内存单元的命名。在C/++程序中,大多数情况下变量声明也就是变量定义,声明变量的同时也就完成了变量的定义,只有声明外部变量时例外。函数类似,声明只是告诉编译器有这个名称、类型的函数,而定义则是函数的真实实现。
简单一句话,定义创建了对象并为这个对象分配了内存,声明没有分配内存。
以下这些就是声明:
extern int bar;
extern int g(int, int);
double f(int, double); // 对于函数声明,extern关键字是可以省略的。
class foo; // 类的声明,前面是不能加class的。
与上面的声明相应的定义如下:
int bar;
int g(int lhs, int rhs) {
return lhs*rhs;}
double f(int i, double d) {
return i+d;}
class foo {
};
2、连接/链接(linkage)
参看:C语言再学习 – 存储类、链接
分为三类,外部连接(链接)(external linkage)、内部连接(链接)(internal linkage)和无连接(链接)(no linkage)。
- 外部连接(链接)(external linkage):对于变量,即无“static”修饰的全局可访问的变量;对于函数,即无“static”修饰的全局可调用的函数。它们即使没有在头文件中用“extern”做外部声明,仍然被识别为外部连接(链接)(external linkage)。
- 内部连接(链接)(internal linkage):即由“static”修饰的全局变量和函数,它们尽可在所在文件内访问和调用,无法被全局访问/调用。
- 无连接(链接)(no linkage):即函数内部变量。所有函数都是有连接(链接,linkage)的。内部变量包含临时变量和静态变量两种,它们的共同特征是均无法在本函数外被访问。
外部链接:
一个具有外部链接的变量可以在一个多文件程序的任何地方使用。
int n = 5; /*文件作用域,外部链接,未使用 static */
int main (void)
{
...
return 0;
}
内部链接:
一个具有内部链接的变量可以在一个文件的任何地方使用。
static int dodgers = 3; /*文件作用域,内部链接,使用了 static ,该文件所私有*/
int main (void)
{
...
return 0;
}
空链接:
具有代码块作用域或者函数原型作用域的变量有空链接,意味着它们是由其定义所在的代码块或函数原型所私有的。
double blocky (double cleo)
{
double patcrick = 0.0; /*代码块作用域,空链接,该代码块所私有*/
int i;
for (i = 0; i < 10; i++)
{
double q = cleo * i; /*q作用域的开始*/
...
patrick * = q;
} /*q作用域的结束*/
return patrick;
}
3、对象(object)
本规范的编制,具有普适性,故会出现如“对象”、“类”这些标准 C 中不提及的概念,对象在 C 语言中的直接对应是变量。当前对象不仅仅是变量,但本译文仅限考虑标准 C(准确的说是嵌入式 C),故不过多描述,我们将其当成“变量”理解即可。
二、规则
每条 MISRA C 准则都可以被归类为“规则”或“指令”。
- 规则:仅对源代码进行分析,即可对规则进行合规性判定,静态分析工具应该具有判定规则的能力,不需要结合人工判定。
- 指令:仅对源代码进行分析,无法对指令进行合规性判定,往往需要结合设计文档或开发人员的经验进行综合判定,静态分析工具可能提供辅助,但不同性能的工具提供的解释可能大不相同。
MISRA C2012将规则和指令均分为三个级别:
- 强制类:必须满足;
- 必要类:应该满足,若不满足应该说明原因;
- 建议类:应该满足,若不满足应该说明原因。
1、标准 C 环境(A standard C environment)
Rule 1.1 程序不得违反标准 C 语法和约束,并且不得超出具体实现的编译限制
- 级别:必要
- 解读:程序应仅使用所选标准版本中指定的 C 语言及其库的功能
- 示例:比如你用C90的编译器你就要符合C90的规则和特性,而不能去使用到C11的特性,其实即使你使用了,编译器也不支持,但不一定都能检测出来,具有一定的风险。
Rule 1.2 不应该使用语言扩展
- 级别:建议
- 解读:不要用编程语言扩展属性,否则会降低程序的可移植性
- 示例: if ((NULL != FuncPointer) && (*FuncPointer())),这样的语句是符合语法的,且就是利用了“一旦确定结果立即停止评估”的特性,在 FuncPointer 值为
NULL 时执行“&&”的右操作数会非常危险,程序会跑到哪完全不可预知。
Rule 1.3 不得发生未定义或严重的未指定行为
- 级别:必要
- 解读:一些未定义或未指定的行为有特定的规则处理。此规则意在防止其他未定义和关键的未指定行为。MISRA C 的许多准则旨在避免某些未定义和未指定的行为。 例如,遵守 Rule 11.4、Rule 11.8 和 Rule 19.2 的所有内容可确保在
C 中不能创建指向使用 const 限定类型声明的对象的非 const 限定指针。这避免了 C90 [Undefined 39]和 C99
[Undefined 61]。
2、未使用的代码(Unused code)
Rule 2.1 项目不得包含不可达代码(unreachable code)
- 级别:必要
- 解读:如果一个程序没有表现出任何未定义的行为,那么无法到达的代码就不能被执行,也不能对程序的输出产生任何影响。因此,无法到达的代码的存在可能表明程序逻辑中的错误。
无法到达的代码会占用目标机器的内存空间,可能会导致编译器在围绕无法到达的代码传输控制时选择更长的、更慢的跳转指令。而且在循环中,它可以防止整个循环驻留在指令缓存中。
- 示例:switch中某个case分支是永远运行不到的,程序员应该删除这种代码。
enum light {
red, amber, red_amber, green };
enum light next_light ( enum light c )
{
enum light res;
switch ( c )
{
case red:
res = red_amber;
break;
case red_amber:
res = green;
break;
case green:
res = amber;
break;
case amber:
res = red;
break;
default:
{
/* 当参数 c 的值不是枚举型 light 的成员时, 此 default 分支才可达 */
error_handler ( );
break;
}
}
return res;
res = c; /* 违规 - 此语句肯定不可达 */
}
Rule 2.2 不得有无效代码(dead code)
- 级别:必要
- 解读:任何可以删除掉但是不影响程序正常运行的代码都是无效代码,由于无效代码可能被编译器删除,所以它的存在可能会引起混乱。
- 示例: 函数 g 不包含无效代码,且其本身也不是无效代码,因为它不含任何操作。但是对它的调用无效,因为删除它不影响程序行为。
void g(void)
{
/* 合规 - 此函数中无任何操作 */
}
void h(void)
{
g(); /* 违规 - 该调用可以被移除 */
}
Rule 2.3 项目不应包含未被使用的类型(type)声明
- 级别:建议
- 解读:如果声明了类型但没有使用,那么审阅者就不清楚该类型是冗余的还是错误地未使用。
- 示例:
int16_t unusedtype(void)
{
typedef int16_t local_Type; /* 违规 */
return 67;
}
Rule 2.4 项目不应包含未被使用的类型标签(tag)声明
- 级别:建议
- 解读:如果一个类型标签被声明但从未被使用过,对于审阅者来说,无法确定该类型标签是多余的还是被错 误闲置的。
- 示例:类型标签 record_t 仅在 record1_t 的类型声明中使用,而在需要使用该类型的位置均使用了 record1_t。此时,我们可以以省略标签的方式声明类型以满足本规则要求,如 record2_t。
typedef struct record_t /* 违规 */
{
uint16_t key;
uint16_t val;
} record1_t;
typedef struct /* 合规 */
{
uint16_t key;
uint16_t val;
} record2_t;
Rule 2.5 项目不应包含未被使用的宏(macro)声明
- 级别:建议
- 解读:如果一个宏被声明但从未被使用过,对于审阅者来说,无法确定该宏是多余的还是被错误闲置的。
- 示例:
void use_macro(void)
{
#define SIZE 4
#define DATA 3 /* 违规 - DATA 未被使用 */
use_int16(SIZE);
}
Rule 2.6 函数不应包含未被使用的执行标签(label)声明
- 级别:建议
- 解读:如果一个执行标签(label)被声明但从未被使用过,对于审阅者来说,无法确定该执行标签是多余的还是被错误闲置的。
- 示例:
void unused_label(void)
{
int16_t x = 6;
label1: /* 违规 */
use_int16(x);
}
tag 和 label,两者翻译为中文都是标签,差别在于tag为枚举、结构体、联合体类型的标签,label为goto语句执行目的地的标签,本文中为区分,将它们分别描述为了类型标签与执行标签。
Rule 2.7 函数中不应有未使用的变量
- 级别:建议
- 解读:绝大多数函数都将使用它们所定义的每一个参数。如果函数中的参数未被使用,则可能函数的实现与其预期定义不匹配。本规则强化描述了这一潜在的不匹配。
- 示例
void withunusedpara(uint1 6_t *para1, int16_t unusedpara) /* 违规 - 参数未使用 */
{
*para1 = 42U;
}
3、注释(Comments)
Rule 3.1 字符序列“/*”和“//”不得在注释中使用
- 级别:必要
- 解读:“/”和“//”均为注释起始的字符序列,如果在一段由“/”起始的注释中,又出现了“/”或“//”,那么很可能是由缺少“/”引起的。如果这两个注释起始的字符序列出现在由“//”起始的注释中,则很可能是因为使用“//”注释掉了代码。
- 示例:在下面 C99 代码的示例中,“//”的出现改变了程序的含义:
x = y // /*
+ z
// */
;
此示例得出的结果是 x=y+z,但在没有两个“//”的情况下,结果是 x=y。
Rule 3.2 “//”注释中不得使用换行(即“//”注释中不得使用行拼接符“\”)
- 级别:必要
- 解读:如果包含“//”注释的源代码行在源字符集中以“\”字符结尾,则下一行将成为注释的一部分。 这可能会导致意外删除代码。
- 示例:在下面的违规示例中,包含 if 关键字的物理行在逻辑上是前一行的一部分,因此是注释。
extern bool_t b;
void f(void)
{
uint16_t x = 0; // comment \
if (b)
{
++x; /* if 语句被作为注释处理, 这里无条件执行 */
}
}
**面试题:**以下注释哪条是错误的??
#include <stdio.h>
int main (void)
{
int /*...*/i;
char* s = "abcd //efg";
//hello \
world!
//in/*...*/t i;
return 0;
前三条注释都是对的,有没有想到。
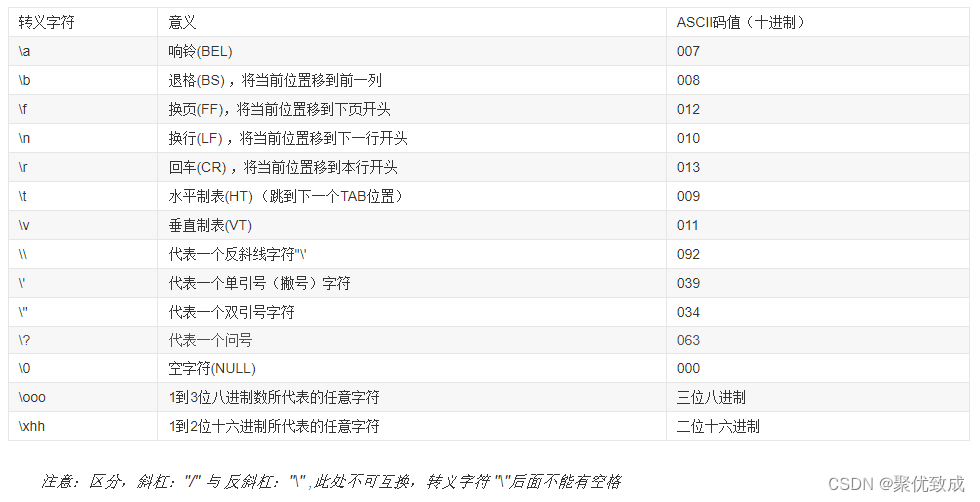
4、字符集和词汇约定(Character sets and lexical conventions)
Rule 4.1 八进制和十六进制转译序列应有明确的终止识别标识
- 级别:必要
- 解读:若八进制或十六进制转译序列后跟随其他字符,会造成混淆。例如,字符串“\x1f”仅由一个字符组成,而字符串“\x1g”则是由两个字符“\x1”和“g”组成。如果给字符常量或字符串文字中的每个八进制或十六进制转义序列增加显示的终止标识,则可以减少混淆的可能性。
- 示例:在此示例中,由 s1,s2 和 s3 指向的每个字符串都等效于字符串“Ag”。
const char *s1 = "\x41g"; /* 违规 - 无法区分哪个是转译序列, 哪个又是普通字符 */
const char *s2 = "\x41" "g"; /* 合规 - 以字符串结束标识转译序列的结束 */
const char *s3 = "\x41\x67"; /* 合规 - 以新的转译序列起始标识前一个转译序列的结束 */
int c1 = '\141t'; /* 违规 - 无法区分哪个是转译序列, 哪个又是普通字符 */
int c2 = '\141\t'; /* 合规 - 以新的转译序列起始标识前一个转译序列的结束 */
参看:C语言再学习 – 转义字符
建议,不使用八进制和十六进制转义序列。
Rule 4.2 禁止使用三字母词(trigraphs)
- 级别:建议
- 解读:三字母词(或叫三联符序列)由两个问号起始,后跟一个特定字符组成。截至目前(2020 年),三字母词只有 9 个:
源代码中的“三字母词”,在编译阶段会被替换为“对应的字符”。 而它们会与两个问号的其他用法引起意外混淆。
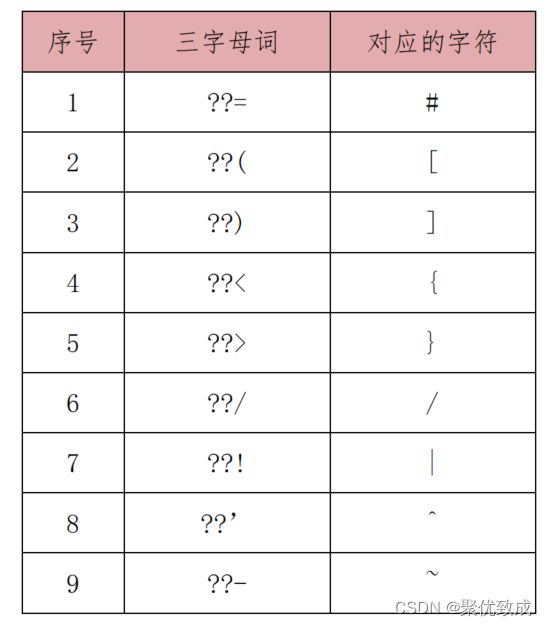
- 示例:
例如,字符串
"(Date should be in the form ??-??-??)"
会被编译器解析为
"(Date should be in the form ~~]"
参看:C语言再学习 – 三字母词(转)
下面是我们很容易犯的一个错误(摘自《C和指针》):
#include <stdio.h>
int main (void)
{
printf("??( \n");
printf("??) \n");
return 0;
}
root@# gcc test.c
test.c: 在函数‘main’中:
test.c:4:10: 警告: 三元符 ??( 被忽略,请使用 -trigraphs 来启用 [-Wtrigraphs]
test.c:5:10: 警告: 三元符 ??) 被忽略,请使用 -trigraphs 来启用 [-Wtrigraphs]
root@# gcc -trigraphs test.c
输出结果:
[
]
注意 :由于编译器的种类各样,对ANSI C的支持也不一样,所以可能会有些C编译器不处理“三字母词”,会将它们当做普通的字符串来处理。 以上测试是在VC++ 6.0下进行的,对于GCC编译器,需要在编译的时候添加选择"-ansi"或者"-trigraphs"。
5、标识符(Identifiers)
Rule 5.1 外部标识符不得重名
- 级别:必要
- 解读:“不重名”取决于实现和所使用的 C 语言版本:在 C90 中,最小有效字符范围是前 6 个字符,且不区分大小写;在 C99 中,最小有效字符范围是前 31 个字符,而其通用字符和扩展字符的有效范围是 6 到 10 个字 符。
- 示例:
在以下示例中,所有定义均出现在同一翻译单元中。 该实现中外部标识符中支持 31 个区分大小写的字符。
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temperature_raw;
int32_t engine_exhaust_gas_temperature_scaled; /* 违规 */
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temp_raw;
int32_t engine_exhaust_gas_temp_scaled; /* 合规 */
全局变量、宏、全局函数等,均需符合此准则,以 C99 为例,前 31 个字符必须不相同,一个有效的办法是,命名少于 31 个字符,且不重名。
Rule 5.2 同范围和命名空间内的标识符不得重名
- 级别:必要
- 解读:如果两个标识符都是外部标识符,则本准则不适用,因为此情况适用于 Rule 5.1。如果每个标识符都是宏标识符,则本准则不适用,因为这种情况已被 Rule 5.4 和 Rule 5.5 涵盖。 “不重名”的定义取决于实现和所使用的 C 语言版本:
◆ 在 C90 中,最低要求是前 31 个字符有效。
◆ 在 C99 中,最低要求是前63 个字符有效,通用字符或扩展源字符视为一个字符。
- 示例:
在下面的示例中,所讨论的实现为:在不具有全局属性的标识符中支持 31 个区分大小写的字符。
/* 1234567890123456789012345678901********* Characters */
extern int32_t engine_exhaust_gas_temperature_raw;
static int32_t engine_exhaust_gas_temperature_scaled; /* 违规 */
void f(void)
{
/* 1234567890123456789012345678901********* Characters */
int32_t engine_exhaust_gas_temperature_local; /* 合规 */
}
/* 1234567890123456789012345678901********* Characters */
static int32_t engine_exhaust_gas_temp_raw;
static int32_t engine_exhaust_gas_temp_scaled; /* 合规 */
Rule 5.3 内部声明的标识符不得隐藏外部声明的标识符
- 级别:必要
- 解读:如果在内部作用域中声明一个标识符,与在外部作用域中已经存在的标识符重名,则最内部的声明将“隐藏”外部的声明。 这可能会导致开发人员混乱。
- 示例:
extern void g(struct astruct *p);
int16_t xyz = 0; /* 定义变量 "xyz" */
void fn2 (struct astruct xyz) /* 违规 - 外部定义的 "xyz" 被同名形参隐藏 */
{
g(&xyz);
}
uint16_t speed;
void fn3(void)
{
typedef float32_t speed; /* 违规 - 类型将变量给隐藏 */
}
参看:C语言再学习 – 存储类、链接
按照C语言作用域划分:
一个C变量的作用域可以是代码块作用域、函数原型作用域,或者文件作用域。
这跟上面的内部外部作用域也不同~~
Rule 5.4 宏标识符不得重名
- 级别:必要
- 解读:本准则要求在定义一个宏时,其命名必须不同于已定义的其他宏的名称,和已定义的参数的名称。它还要求给定宏的参数名称彼此不同,但不要求宏参数名称在两个不同的宏之间不同。
“不重名”的定义取决于实现和所使用的 C 语言版本:
◆ 在 C90 中,最低要求是宏标识符的前 31 个字符有效。
◆ 在 C99中,最低要求是宏标识符的前 63 个字符有效。
- 示例:
在以下示例中,讨论的实现为:宏标识符中支持 31 个区分大小写的有效字符。
/* 1234567890123456789012345678901********* Characters */
#define engine_exhaust_gas_temperature_raw egt_r
#define engine_exhaust_gas_temperature_scaled egt_s /* 违规 */
/* 1234567890123456789012345678901********* Characters */
#define engine_exhaust_gas_temp_raw egt_r
#define engine_exhaust_gas_temp_scaled egt_s /* 合规 */
Rule 5.5 宏标识符与其他标识符不得重名
- 级别:必要
- 解读:宏名称和标识符保持不同有助于避免开发人员混淆。
- 示例:
在下面的违规示例中,类似函数的宏 Sum 的名称也用作标识符。对象(变量)Sum 的声明不进行宏展开,在这里插入代码片因为它后面没有“(”字符。因此,标识符在进行预处理后仍存在。
#define Sum(x, y) ((x) + (y))
int16_t Sum; /* 违规 - 上面的宏Sum 与该变量重命名 */
typedef 名称应是唯一标识符
- 级别:必要
- 解读:如果多个 typedef 名称命名相同而它们实际指代又是不同的函数、对象或枚举常量时,开发人员会被困扰。
- 示例:
void func ( void )
{
{
typedef unsigned char u8_t;
}
{
typedef unsigned char u8_t; /* 违规 - 重复使用 */
}
}
typedef float mass;
void func1 ( void )
{
float32_t mass = 0.0f; /* 违规 - 重复使用 */
}
typedef struct list
{
struct list *next;
uint16_t element;
} list; /* 合规 - 符合例外的情况 */
typedef struct
{
struct chain
{
struct chain *list;
uint16_t element;
} s1;
uint16_t length;
} chain; /* 违规 - 标记 "chain" 与 typedef 不关联 */
Rule 5.7 标签(tag)名称应是唯一标识符
- 级别:必要
- 解读:重用标签(tag)名称可能会导致开发人员混乱。这里的标签tag为枚举、结构体、联合体类型的标签。
- 示例:
struct stag
{
uint16_t a;
uint16_t b;
};
struct stag a1 = {
0, 0 }; /* 合规 - 与前面的定义一致 */
union stag a2 = {
0, 0 }; /* 违规 - 与声明的 struct stag 不一致。
* 同时也违背了C99的约束 */
Rule 5.8 全局(external linkage)对象和函数的标识符应是唯一的
- 级别:必要
- 解读:用作外部标识符的标识符不得在任何命名空间或编译单元中用于任何其他目的,即使它没有链接的对象。
- 示例:
/* file1.c */
int32_t count; /* "count" 具有全局属性(全局变量) */
void foo ( void ) /* "foo" 具有全局属性(全局函数) */
{
int16_t index; /* "index" 无全局属性(临时变量) */
}
/* file2.c */
static void foo ( void ) /* 违规 - “ foo”不唯一(在file1.c中有全局属
* 性的同名函数) */
{
int16_t count; /* 违规 - "count" 没有全局属性, 但与另一文
* 件的有全局属性的变量重名 */
int32_t index; /* 合规 - "index"无全局属性(临时变量) */
}
Rule 5.9 局部全局(internal linkage)对象和函数的标识符应是唯一的
- 级别:建议
- 解读:标识符名称在所有命名空间和编译单元中都应该唯一。任何标识符都不应与任何其他标识符具有相同的名称,即使该其他标识符没有链接的对象也是如此。
- 示例:
/* file1.c */
static int32_t count; /* "count" 局部全局属性 */
static void foo ( void ) /* "foo" 局部全局属性 */
{
int16_t count; /* 违规 - "count" 没有全局属性, 但与有局部全
* 局属性的标识符冲突 */
int16_t index; /* "index" 无全局属性 */
}
void bar1 ( void )
{
static int16_t count; /* 违规 - "count" 没有全局属性, 但与有局部全
* 局属性的标识符冲突 */
int16_t index; /* 合规 - "index" 不唯一但它没有与其冲突的具全
* 局属性的标识符 */
foo ( );
}
/* End of file1.c */
/* file2.c */
static int8_t count; /* 违规 - "count" 具有局部全局属性, 与另一个
* 具有局部全局属性的标识符重复 */
static void foo ( void ) /* 违规 - "foo" 具有局部属性, 与另一个具有局
* 部属性的函数标识符重复 */
{
int32_t index; /* 合规 - "index" 和 "nbytes" */
int16_t nbytes; /* 不唯一, 但因都不具全局属性, 因而不冲突 */
}
void bar2 ( void )
{
static uint8_t nbytes; /* 合规 - "nbytes" 不唯一, 但它没有全局属性,
* 全局属性与存储类别无关 */
}
/* End of file2.c */
6、类型(Types)
Rule 6.1 位域(位带)仅允许使用适当的类型来声明(位域成员类型限制)
- 级别:必要
- 解读:“适当的”位域类型为:
◆ C90:unsigned int 或 signed int;
◆ C99:下列几种之一:
unsigned int 或 signed int;
实现允许的其他显示声明的有符号或无符号整数类型;
_Bool
- 示例:
以下示例适用于不提供任何其他位域类型的 C90 和 C99 实现。假定 int 类型为 16 位。
typedef unsigned int UINT_16;
struct s {
unsigned int b1:2; /* 合规 */
int b2:2; /* 违规 - 不允许使用不明确符号的"int" */
UINT_16 b3:2; /* 合规 - 由typedef声明的"unsigned int" */
signed long b4:2; /* 违规 - 即使 long 和 int 大小相同 */
};
。。。。。
MISRA 后面补充~~~~
三、Eclipse编码环境设置
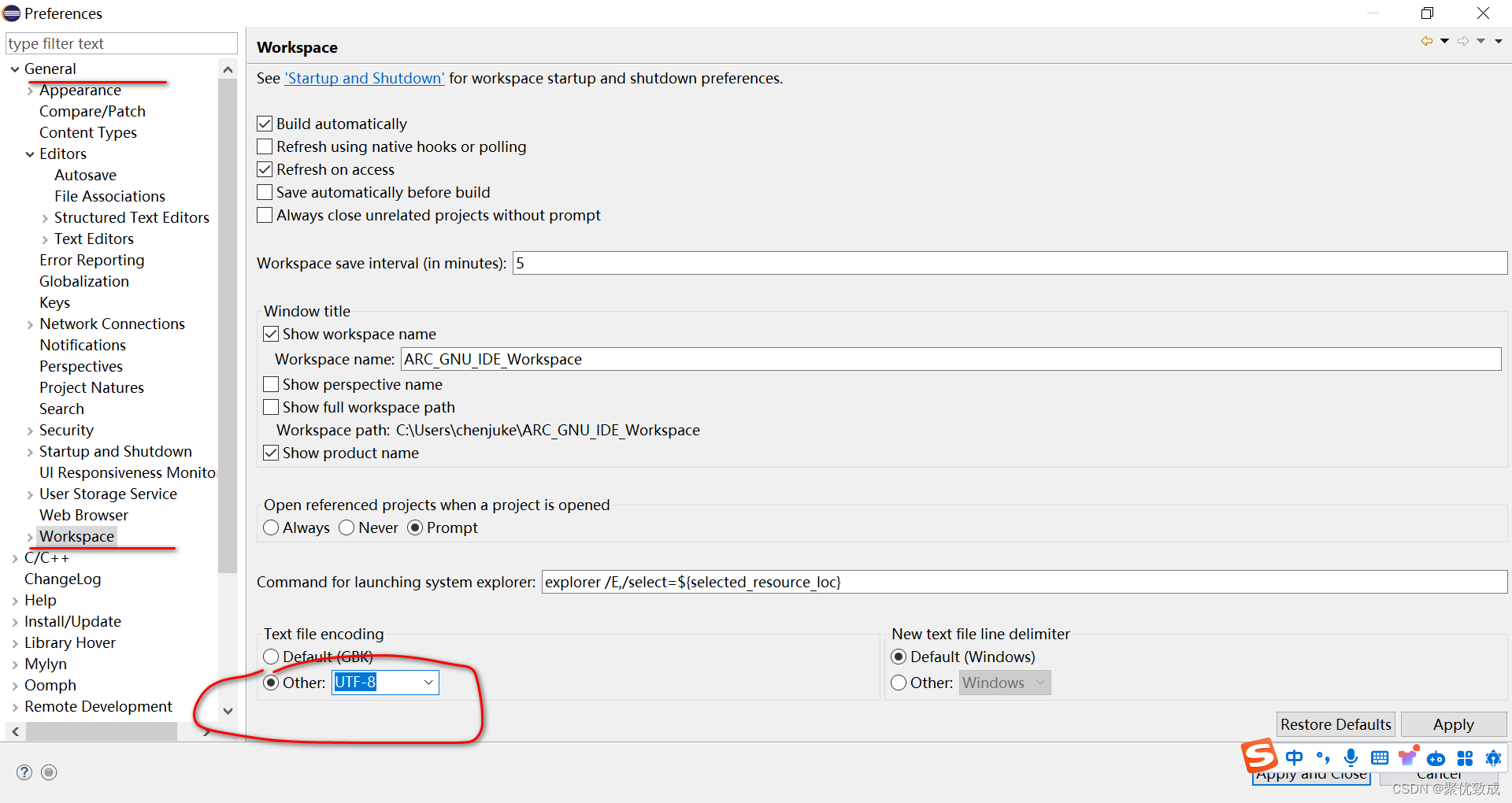
1、设置工作区的编码格式为UTF-8
window > Preferences > General > Workspace > Text file encoding
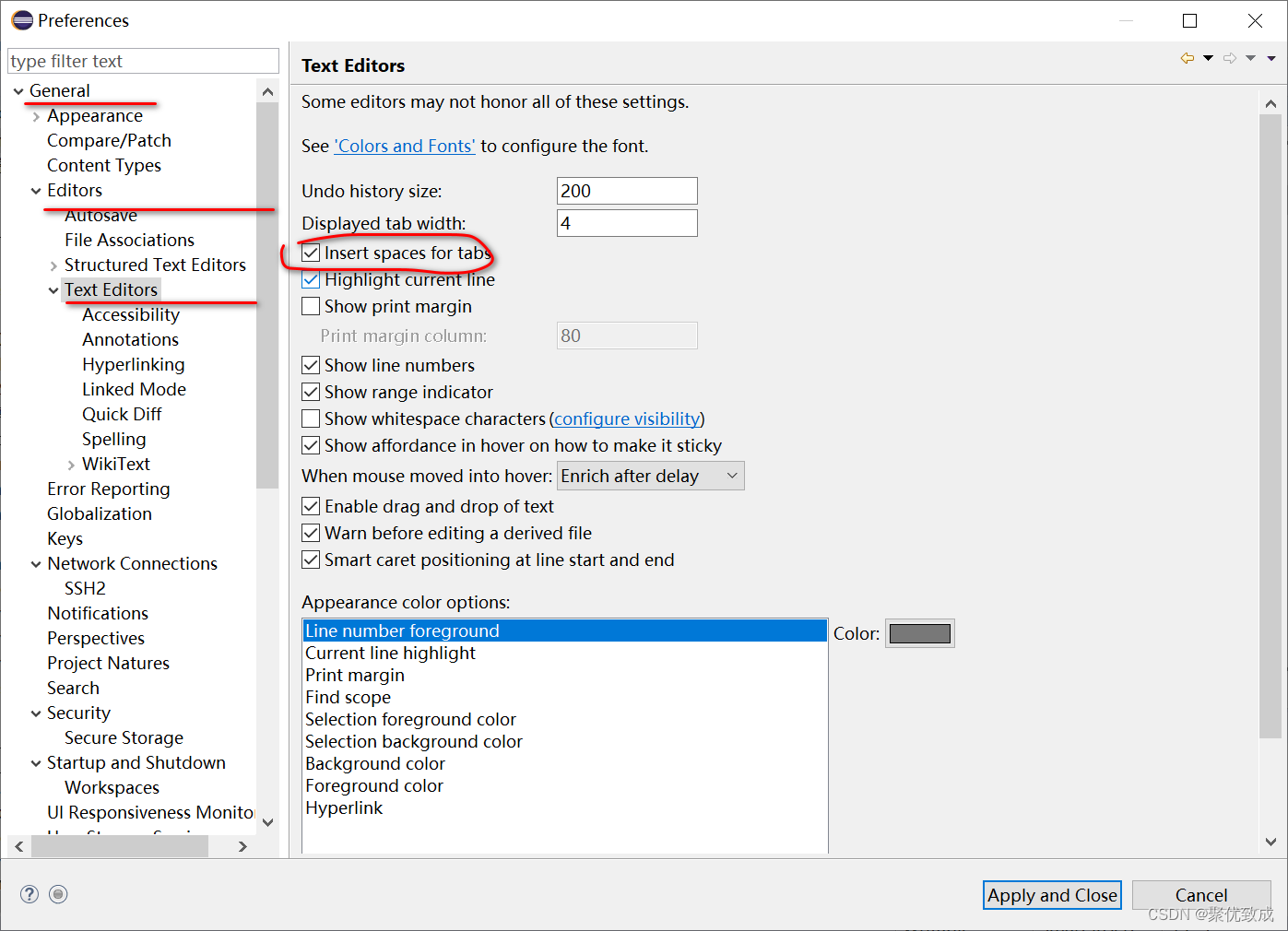
2、设置Tab键为4个空格
window > preference > General > Editors > Text Editors 选中右侧的insert space for tabs
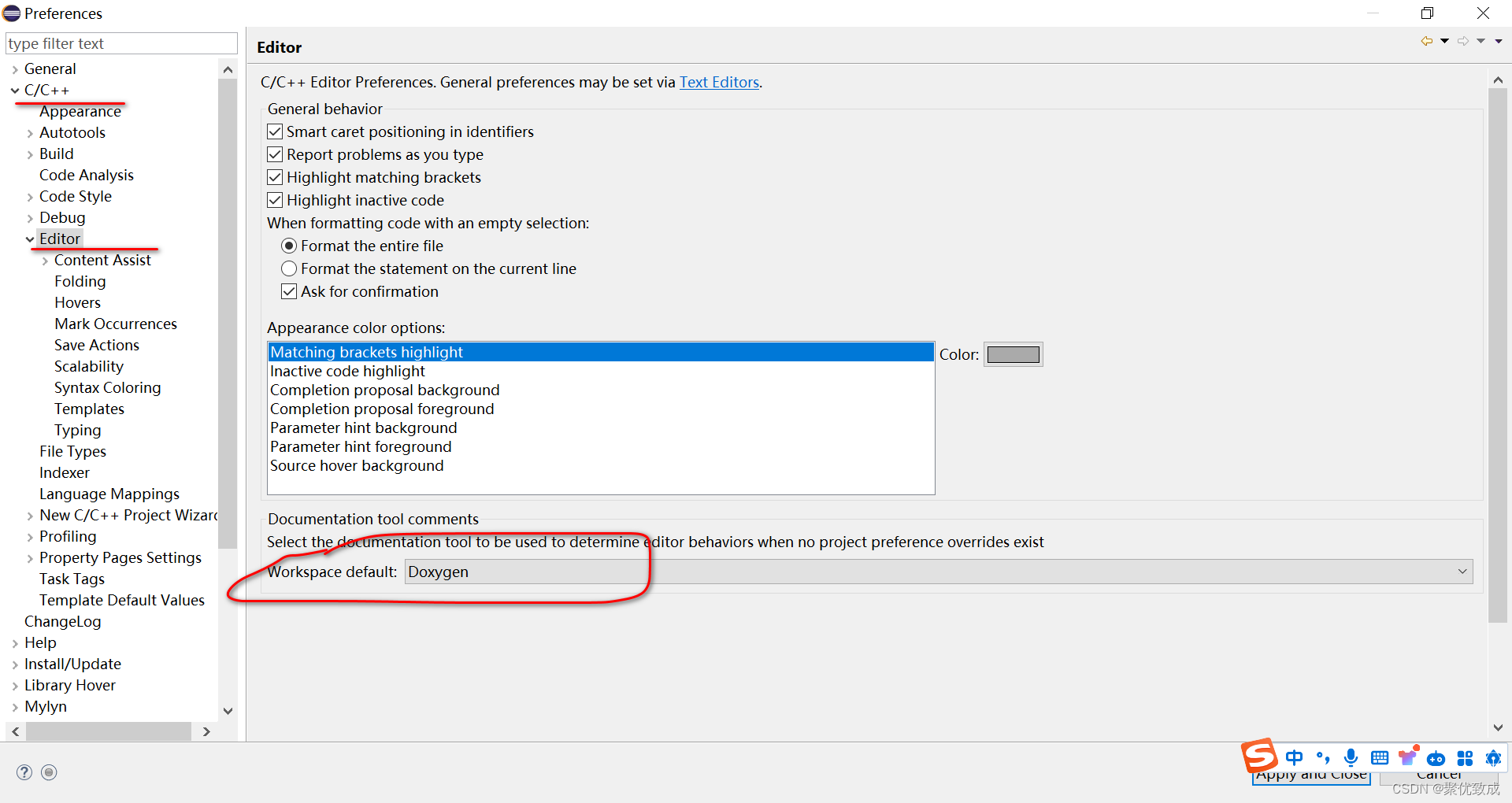
3、设置支持Doxy风格的注释
window > preference > Editor 将workspace default 设置为Doxygen
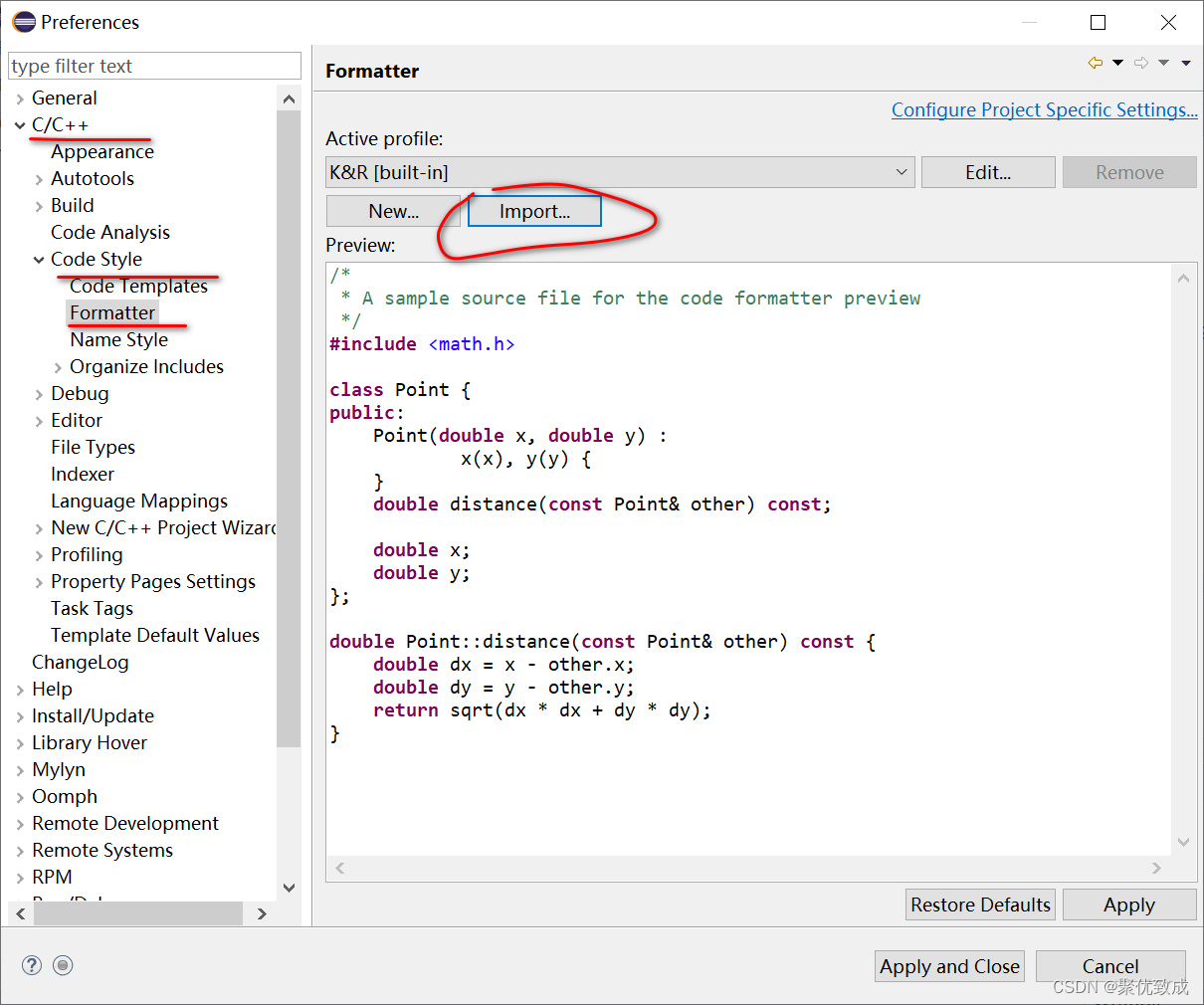
4、自动排版模板设置
window->preference->C++->code style->Formatter,在右侧点击Import…选择
xxx.xml。
四、编程规范
1、注释
文件头注释
所有文件(如源文件.c,头文件.h文件,.inc文件,.def文件,编译说明文件.cfg等)头部应进行注释,注释必须列出:版权说明、版本号、生成日期、作者、功能描述、修改日志等,源文件和头文件的注释中还应有模块功能简要说明。
/**
* Copyright(C), Tech. Co., Ltd.
* @brief ${project_name}
* @file ${file_name}
* @author ${user}
* @date ${date}
* -History:
* -# author: xx, date: 2022-12-27, Version:
* details:
* -# Please add new commit here.
**/
函数头注释
函数头部应进行注释,列出:函数的目的/功能、输入参数、输出参数、返回值、调用关系(函数、表)等。
/**
* @brief main
* @param argc numbers of parameter
* @param argv pointer array of parameter
* @return success or failed
* @retval 0 success
* @retval 1 failed
* @details program entrance
**/
int main(int argc, char* argv[])
{
//TODO
}
注释原则
- 一般情况下,源程序有效注释量必须在20%以上。
说明:注释的原则是有助于对程序的阅读理解,在该加的地方都加了,注释不宜太多也不能太少,注释语言必须准确、易懂、简洁。 - 注释的内容要清楚、明了,含义准确,防止注释二义性。
- 对于所有有物理含义的变量、常量,如果其命名不是充分自注释的,在声明时都必须加以注释,说明其物理含义。变量、常量、宏的注释应放在其上方相邻位置或右方。
/* active statistic task number */
#define MAX_ACT_TASK_NUMBER 1000
#define MAX_ACT_TASK_NUMBER 1000 /* active statistic task number */
- 数据结构声明(包括数组、结构、类、枚举等),如果其命名不是充分自注释的,必须加以注释。对数据结构的注释应放在其上方相邻位置,不可放在下面;对结构中的每个域的注释放在此域的右方。
- 重要的全局变量要有较详细的注释,包括对其功能、取值范围、存取时注意事项等进行说明。
- 注释与所描述内容进行同样的缩排。
void ExampleFunc ()
{
/* This is dead loop */
DeadLoopFunc();
}
- 对变量的定义和分支语句(条件分支、循环语句等)必须编写注释。
- 禁止在一行代码或者表达式的中间插入注释。
- 不要使用汉语拼音进行注释。
- 禁止使用
’//’或’/*’进行注释。注释只能用/* */标识符。 - 代码段不应该被注释掉。
2、标识符命名
命名总则
- 标识符的命名要清晰、明了,有明确含义,同时使用完整的单词或大家基本可以理解的缩写,避免使人产生误解。
temp 可缩写为 tmp ;
flag 可缩写为 flg ;
statistic 可缩写为 stat ;
increment 可缩写为 inc ;
message 可缩写为 msg ;
- 命名中若使用特殊约定或缩写,则要有注释说明。
- 对于变量命名,禁止取单个字符(如i、j、k…),建议除了要有具体含义外,还能表明其变量类型、数据类型等,但i、j、k作局部循环变量是允许的。
- 标识符命名长度不能超过31个字符。
- 标识符命名不能使用中文或拼音。
- 外部标示符不能相同,而且不能使用大小写进行区别分。
unsigned int abc = 111;
unsigned int ABC = 123; /* Non-compliant */
- 相同作用范围内的标示符命名不能相同,而且不能使用大小写进行区分。
void function()
{
unsigned int abc = 111;
unsigned int ABC = 111; /* Non-compliant */
}
- 宏(常量或函数)的名称不能与另一个宏或另一个标识符相同。
- 类型定义的名称必须是独一无二的标识符。
- 标签的名称必须是独一无二的标识符。
- 对象或函数的标识符必须是独一无二的标识符。
- 标识符命名时第一个字符和最后一个字符不能是‘_’。
- 变量命名不能使用编译器或编程语言的保留字。比如data、register等。
函数命名
- 函数命名可以选择以下两种方式中的一种。不可以使用第三种命名方式。
字母全部小写:init_spi()
驼峰式命名法:initSpi()
变量命名
- 变量名称应该具有明确的意义。
uint16_t giMemorySize;
uint16_t maArray[10];
uint16_t *piPointer;
- 变量名称应该增加前缀以标明变量的作用范围或数据类型。
Array a...
BOOL b...
UINT n...
int i...
short n...
long l...
WORD w...
DWORD dw...
float f...
char c...
global glb
local loc
member m_
pointer prt
- 变量名称应该采用驼峰命名法。不要使用其他的命名方式。
驼峰命名法:glbCntNum - 定义常量时在标识符前增加const,命名规则不变。
宏命名
- 宏定义,常量,枚举值应该使用全部大写字母。宏名称应该能够明确表示宏的意义。
#define CALCULATION_PARAMETER 100
- 枚举,常量,宏定义中每个单词之间使用‘_’进行连接。
3、代码设计
- 具有重叠可见性的同名空间中的标识符应该在印刷上明确无误。
具有相似外形的字母大写和小写要区分。
是否存在下划线的标识符。
互换大写字符“O”和数字“0”
互换大写字符“I”和数字“1”
互换大写字符“I”和小写字符“l”
互换小写字符“l”和数字“1”
- 在使用typedef以替换基本数据类型时应该标识出数据长度和有无符号。
typedef signed char int8_t;
typedef unsigned char uint8_t;
typedef signed short int16_t;
typedef unsigned short uint16_t;
typedef signed int int32_t;
typedef unsigned int uint32_t;
- 如果函数的返回值是一个错误信息,那么该错误信息应该被检查。
- 应该在头文件中定义预编译宏来防止头文件被包含的次数不止一次。
#ifndef SPI_H
#define SPI_H
…/* Contents of file */
#endif
- 不要使用动态内存分配。
- 要时刻注意易混淆的操作符。当编完程序后,应从头至尾检查一遍这些操作符,以防止拼写错误。
形式相近的操作符最容易引起误用,如C/C++中的“=”与“==”、“|”与“||”、“&”与“&&”等,若拼写错了,编译器不一定能够检查出来。
如把“&”写成“&&”,或反之。
ret_flg = (pmsg->ret_flg & RETURN_MASK);
被写为:
ret_flg = (pmsg->ret_flg && RETURN_MASK);
rpt_flg = (VALID_TASK_NO( taskno ) && DATA_NOT_ZERO( stat_data ));
被写为:
rpt_flg = (VALID_TASK_NO( taskno ) & DATA_NOT_ZERO( stat_data ));
- 编程时,要防止差1错误。
此类错误一般是由于把“<=”误写成“<”或“>=”误写成“>”等造成的,由此引起的后果,很多情况下是很严重的,所以编程时,一定要在这些地方小心。当编完程序后,应对这些操作符进行彻底检查。
冗余代码
- 一个工程中不能包含不可达代码。
uint16_t GetValue()
{
return rtn_Value;
rtn_Value++; /* Non-Compliant, this is unreachable code */
}
- 一个工程中不能包含不被执行的语句。
extern uint16_t *p;
void f(f)
{
*p++; /* Non-compliant, result is not used */
(*p)++; /* Compliant, *p is incremented */
}
switch语句的Default分支作为保护作用是一个例外。
- 一个工程中不能包含未使用的类型声明。
- 一个工程中不能包含未使用的标签声明。
- 一个工程中不应该包含未使用的宏定义。
- 一个函数中不能包含未使用的参数。
4、可读性
- 注意运算符的优先级,并用括号明确表达式的操作顺序,避免使用默认优先级。
- 禁止使用数字直接参与判断或者运算,必须封装成宏,变量或者数组等,除非是无意义的0可以直接使用。
例如:
c = a + 0x16u;
应该变更为
/* .h */
#define NUMBER 0x16u
/* .c */
c = a + NUMBER;
- 不要使用复合语句,尽量一条语句实现一个功能。
如下表达式,考虑不周就可能出问题,也较难理解。
stat_poi ++ += 1;
++ stat_poi += 1;
应分别改为如下:
stat_poi += 1;
stat_poi++; // 此二语句功能相当于“ * stat_poi ++ += 1; ”
- 循环体内工作量最小化。
应仔细考虑循环体内的语句是否可以放在循环体之外,使循环体内工作量最小,从而提高程序的时间效率。
for (ind = 0; ind < MAX_ADD_NUMBER; ind++)
{
sum += ind;
back_sum = sum; /* backup sum */
}
语句“back_sum = sum;”完全可以放在for语句之后,如下。
for (ind = 0; ind < MAX_ADD_NUMBER; ind++)
{
sum += ind;
}
back_sum = sum; /* backup sum */
5、定义与声明
- 定义和声明时要明确规定数据类型。
static uint16_t g_Number = 0x00;
static void f(void){
}
不可以出现如下情况:
static g_Number = 0x00;
static f();
- 一个对象或函数的所有声明都应该使用相同的名称和类型限定符
static void function(void); /* A function declaration*/
static void function(void)
{
…/* program code */
}
- 当定义一个具有外部链接的对象或函数时,也要进行与之相匹配的显性声明。
extern void function1(void);
void function(void)
{
…/*program code*/
}
- 一个外部对象或外部函数应该在且仅在一个文件中被声明。
- 一个具有外部链接的标识符应该只有一个外部定义。
/* file 1 */
int16_t number = 10;
/* file 2 */
int16_t number = 20; /* Non-Compliant,two definition of number */
- 如果函数或对象只在一个编译单元中被引用,那么他们不应该被定义为外部链接。
- 所有只具有内部链接的对象或函数都应该被声明为静态存储类型(static)。
- 如果一个对象的标识符只在单一一个函数中出现,那么该对象应该在函数区块内定义为局部变量。
- 内联函数应该被声明为静态存储类型(static)。
- 当一个具有外部链接的数组声明时,其数组大小应该被精确定义。
/* .h */
extern uint16_t g_Array[10];
/* .c */
uint16_t g_Array[10] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
- 在枚举列表中,每个枚举常量的值都应该明确给出且应该声明其数据类型。
enum ECU_Mode_List
{
INIT_MODE = (uint16_t)0x00u,
WORK_MODE = (uint16_t)0x01u,
DIAG_MODE = (uint16_t)0x02u,
SAFE_MODE = (uint16_t)0x03u,
SLEP_MODE = (uint16_t)0x04u,
NoofMode = (uint16_t)0x05u
};
- 指针变量应该尽可能指向const值。
当指针的作用不是以下情况时,应该尽可能定义为const指针。
指针被用于修改对象。
指针是被另一个指向非const指针拷贝以用于: 分配内存;内存数据转移或者被备份函数使用。
- 不应使用限制类型限定符
void user_copy(void *restrict p, void * restrict q, size_t n)
6、初始化
- 一个自动分配存储地址的对象在调用或读取之前必须初始化。
- 除非数组或结构体中所有变量的初值都是0,否则必须对每一个元素进行单独初始化。
- 聚合体或联合体的初始化值应该用{}括起来。
uint16_t Array[10] = {
0};
typedef struct
{
uint16_t a;
uint16_t b;
uint16_t c;
}structObj;
structObj Object = {
0x01, 0x02, 0x03};
- 对象中的元素被初始化的次数不能超过一次。
- 在初始化数组之前,数组的长度应该被显式表示出来。
uint16_t Array[] = {
0, 1, 2, 3};
不建议上述初始化方法。应该使用以下方法进行初始化。
uint16_t Array[4] = {
0, 1, 2, 3};
- 结构体初始化过程中大括号应该与其内部结构相匹配。
typedef struct
{
uint32_t m_SOF; /* Start of frame */
uint32_t m_Frame_ID; /* Frame ID */
uint32_t m_TIME_ST; /* Global time stamp */
int8_t m_AllDTCNo; /* All support DTC number */
int8_t m_DTC_Mask; /* All support status masks */
int8_t m_FramSize; /* Frame size */
int8_t m_StatusChanged; /* Status changed flag */
uint32_t m_Paddings[3]; /* Reserved */
uint32_t m_PowerOn_CNT; /* Power on counter */
}DTC_Frame_Head;
对应的结构体初始化时如下:
static DTC_Frame_Head l_SOF =
{
0xAA55AA55,
0x00000000,
0x00000000,
0x00,
0x00,
0x00,
0x00,
{
0x00000000,0x00000000,0x00000000},
0x00000000};
数据类型规范
- 对数据的操作应该符合其数据类型。
不可以对布尔值进行移位操作。
不可以对布尔值进行加减乘除操作。
不可以对布尔值进行求余操作。
不可以对布尔值进行位与,位或,求反操作。
不可以对有符号数进行移位操作。
不可以对8位char值进行乘除,求余,移位操作等。
不可以对float数进行移位操作。
- 数据进行计算时必须考虑数据类型之间的差异。如果数据类型不同,则需要先向表达式内最宽数据范围的数据类型进行显式强制转换,然后再进行计算。
uint16_t a = 10;
uint8_t b = 8;
b = a + b; /* Non-compliant */
应该按照下面的操作进行。
uint16_t c;
c = a + (uint16_t)b;
- 表达式赋值时不应该向更窄的数据类型或者完全不同的数据类型进行赋值或计算操作。
uint16_t u16a = 3000u;
uint8_t u8b = 50u;
u8b = u16a + u8b; /* Non-compliant */
上述赋值操作会导致数据丢失。
uint16_t u16a = 3000u;
uint8_t u8b = 50u;
uint16_t u16c = 0u;
u16c = u16a + (uint16_t)u8b; /* Compliant */
u16a = 0.1f /* Non-compliant */
u16a = -2 /* Non-compliant */
- 当表达式在使用变量时,要注意变量的数据类型。如果数据类型错误可能造成无法预计的错误。
uint8_t i = 0;
for(i = 0; i <= 1000; i++)
{
…/* Non-compliant */
}
- 复合表达式在计算前要进行显性强制数据转换,然后再进行计算。
uint16_t u16a = 5000u;
uint8_t u8b = 10u;
uint32_t u32c = 0u;
u32c = (uint32_t)u16a + (uint32_t)u8b;
- 数据类型的定义应该具有统一的格式,且应该在所有工程中统一。
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned long int uint32_t;
typedef signed char int8_t;
typedef short int int16_t;
typedef long int int32_t;
typedef boolean bool_t;
typedef float float32_t;
typedef double double64_t;
7、表达式和副作用
- 编程人员要明确表达式的优先级,但是不要过分依赖优先级进行编程。
x = y + z * a;
应该写成
x = y + (z * a);或者 x = (y + z)*a;
- 赋值” = ”表达式右侧如果执行移位操作,则其移位的位数应该保持在左侧数据类型范围内。
u8a = u8a << 7; /* Compliant */
u8a = u8a << 8; /* Non-compliant */
u16a = (uint16_t)u8a << 10; /* Compliant */
1u << 10u /* Non-compliant */
(uint16_t)1u << 10u /* Compliant */
1UL << 10u /* Compliant */
- 禁止使用” , ”运算符。
uint16_t g_Counter = 0;
uint8_t i = 0;
for(i = 0; i < 100; i++, g_Counter++)
{
/* Non-compliant */
}
以上代码应该改为:
for(i = 0; i < 100; i++)
{
…/* program code */
g_Counter++
}
- 在使用表达式的判断条件时不要引起数据溢出。
uint8_t i = 0;
for(i = 0; i <= 512; i++)
{
}
- 表达式中如果包含自增(++)或自减(–)操作时,除了自增和自减操作外不能包含其他可能造成副作用的操作。
uint8_t a = 1;
if((a--) == 0)
{
/* Non-compliant */
}
应该写成:
a--;
if(a == 0)
{
…/*program code*/
}
- 在一个表达式中不要直接使用赋值运算的结果。
uint8_t x = 10u;
uint8_t y = 20u;
if((x = y)>15)
{
…/* Non-compliant */
}
else
{
/* Do nothing */
}
上述应该写为以下形式:
x = y;
if(x > 15)
{
…/* program code */
}
else
{
/*Do nothing*/
}
- 逻辑&&和逻辑||操作符号的右侧不应该包含副作用。
由于逻辑&&和逻辑||的右侧是左侧值的判断条件。所以如果具有副作用可能会造成与程序预期不符合的判断结果。
if(ishigh || (a == f(x)))
{
/*Non-compliant*/
}
- 不能在具有副作用的表达式中使用sizeof 运算符。
s = sizeof(j++); /* Non-compliant */
8、条件语句与循环语句
- 循环计数条件不能是一个float类型的数据。
uint32_t counter = 0u;
for(float32_t f = 0.0f; f < 1.0f; f += 0.001f)
{
++counter;
}
上述编程方式是错误的,需要重写为以下形式:
float32_t f = 0.0f;
for(uint32_t counter = 0u; counter < 1000u; ++counter)
{
f = (float32_t)counter * 0.001f;
}
- for语句的组成规范。
for(a, b, c)语句在使用中需要对a,b,c三个位置进行填写。针对填写内容进行以下规范。
a位置: 可以不进行填写。也可以填写循环计数器的初值。
b位置: 应该填写一个不具有副作用的表达式。 应该包含循环计数器和循环控制判断条件。不能包含任何在循环体内被改变内容的对象。
c位置: 包含一个仅改变循环计数器值的表达式。 不能包含任何在循环体内被改变的对象。 例外:允许使用for(;;)作为无限循环的循环体。
- 控制条件表达式的布尔运算结果不能永远不变。
s8a = (u16a < 0u)? 0 : 1; /* Non-compliant, u16a always >= 0 */
- if语句和while语句的控制表达式必须具有一个布尔类型的结果。
int32_t i32a = 0;
if(i32a)
{
/* Non-compliant */
}
应该写成:
if(i32a != 0)
{
}
- switch 语句按照以下格式进行编程。
switch(state)
{
case CONDITION_1:
{
…/*program code*/
break;
}
case CONDITION_2:
{
…/*program code*/
break;
}
…………
case CONDITION_N:
{
…/*program code*/
break;
}
default:
{
…/*program code*/
break;
}
}
- switch中的每个条件下的语句必须在本条件下完成操作,不能跨条件进行操作。
switch(x)
{
case CONDITION_1:
if(a == 0)
{
case CONDITION_2:
b = 0;
}
break;
}
- 每个switch判断条件都要用一个break结束。
- 每个switch语句都要带有一个default判断。
switch语句的最后一个条件必须是default,无论是否能够执行。而且default应该放在switch语句的最后一个条件。 - switch语句中的判断条件除了default之外还应该至少有两个case。
条件过少的情况下建议不要使用switch语句而改为if语句。 - switch语句的判断条件不能是一个布尔数据类型的值。
switch(x == 0) /*Non-compliant, this is boolean value.*/
{
case 0:
break;
case 1:
break;
}
- 禁止使用continue语句。
- 不要滥用goto语句。
9、函数
- 不要使用库函数<stdarg.h>中的功能。
该库中的函数不支持C90和C99 - 禁止函数自己调用自己,无论直接还是间接调用。
- 禁止对函数进行隐式声明
如果在另一个函数中调用这个函数,但是这个函数没有进行声明,那么会出现未知的情况。 - 带有non-void 返回类型的函数其所有退出路径都应具有显式的带表达式的return 语句。
表达式给出了函数的返回值。如果return 语句不带表达式,将导致未定义的行为(而且编译器不会给出错误)。 - 如果调用函数时输入的参数是一个数组,那么函数定义的输入数组长度必须大于或等于实际数组的长度。
int16_t Array_1[5];
int16_t Array_2[4];
void f1(int16_t inputA[4])
{
}
void f2(int16_t inputB[])
{
}
f1(Array_1); /* Non-compliant, size of Array_1 is larger than f1 input array. */
f1(Array_2); /* Compliant */
f2(Array_1); /* Compliant */
- 如果一个函数具有返回值,但是在调用函数时不使用返回值,应该在调用前转换为void类型。
int16_t f(void)
{
…/* program code */
}
调用时如下:
(void)f();
10、指针和数组
- 如果一个指针是指向数组的,那么该指针指向的地址不能超过数组长度。
int16_t Array[10];
int16_t *pointer;
pointer = &Array[0];
pointer = &Array[9];
pointer = &Array[10]; /*Non-compliant, pointer is out of range.*/
- 指针减法只能用在指向同一数组中元素的指针上。
-
、>=、<、<= 不应用在指针类型上,除非指针指向同一数组。
- +,-, +=和-=操作不能使用在指针类型的表达式上。
uint8_t *ptr;
*(ptr + 5) = 0u; /* Non-compliant */
ptr[5] = 0u; /* Compliant */
- 如果一个自动存储地址的对象可能会被释放,那么该对象的地址不应该被传递给一个在它释放后仍然存在的对象。
uint8_t *f(void)
{
uint8_t Local;
return &Local; /* Non-compliant */
}
- 定义数组时必须定义数组长度。
- 不能使用变量来定义指针长度。
如果变量是0或者负数,那么该行为将造成未知影响。
11、预处理命令
- 文件中的
#include语句之前只能是其他预处理指令或注释。 - 在头文件名称中不能出现
” , ”或” \ ”以及” /* ”和” // ”等非标准字符。
如果在头文件名字预处理标记的 < 和 > 限定符或 ” 和 ” 限定符之间使用了 ‘ ,\ ,或 /* 字符,该行为是未定义的。
- 宏命令
#include只能跟随< filename >或” filename ”序列。 - 一个宏不能与另一个关键字相同。
- 禁止使用
#undef。 - 看起来像预处理命令的标记不应该出现在宏参数中。
- 如果通过宏函数表达式进行计算,那么输入的参数需要用小括号括起来。
#if或#elif预处理命令的控制表达式结果应该是0或1。
#if 0, #if 1, #if A > B
- 所有标识符在用于
#if或#elif预处理命令之前必须先用#define进行定义。 - 不要使用# 或 ## 预处理器操作符。
- 在单一的宏定义中最多可以出现一次 # 或 ## 预处理器操作符。
#if,#elif和#endif应该尽可能靠近且关系清晰,以防止预处理指令执行混乱。
智能推荐
Failed to discover available identity versions when contacting http://controller:35357/v3. 错误解决方式_caused by newconnectionerror('<urllib3.connection.-程序员宅基地
文章浏览阅读8.3k次,点赞5次,收藏12次。作为 admin 用户,请求认证令牌,输入如下命令openstack --os-auth-url http://controller:35357/v3 --os-project-domain-name default --os-user-domain-name default --os-project-name admin --os-username admin token issue报错Failed to discover available identity versions whe._caused by newconnectionerror('
学校机房统一批量安装软件的方法来了_教室电脑 一起装软件-程序员宅基地
文章浏览阅读4.5k次。可以在桌面安装云顷还原系统软件,利用软件中的网络对拷功能部署批量对拷环境,进行电脑教室软件的批量对拷安装与增量对拷安装。_教室电脑 一起装软件
消息队列(kafka/nsq等)与任务队列(celery/ytask等)到底有什么不同?_任务队列和消息队列-程序员宅基地
文章浏览阅读3.1k次,点赞5次,收藏7次。原文链接:https://www.ikaze.cn/article/43写这篇博文的起因是,我在论坛宣传我开源的新项目YTask(go语言异步任务队列)时,有小伙伴在下面回了一句“为什么不用nsq?”。这使我想起,我在和同事介绍celery时同事说了一句“这不就是kafka吗?”。那么YTask和nsq,celery和kafka?他们之间到底有什么不同呢?下面我结合自己的理解。简单的分析一..._任务队列和消息队列
Java调KT类_java 调用kt 对象-程序员宅基地
文章浏览阅读1.5k次。1,MyUtuils.kt将被调用的文件class MyUtils { fun show(info:String){ println(info) }}fun show(info:String){ println(info)}2,Java文件调用该类,ClientJava.javapublic class ClientJava { public static void main(String[] args) { /** _java 调用kt 对象
UDP报文最大长度_最大请求报文大小-程序员宅基地
文章浏览阅读6.6k次,点赞4次,收藏4次。在进行UDP编程的时候,我们最容易想到的问题就是,一次发送多少bytes好? 当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的,我这里仅对 像ICQ一类的发送聊天消息的情况作分析,对于其他情况,你或许也能得到一点帮助: 首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层. UDP属于运输层_最大请求报文大小
Windows CMD命令行程序中 无限死循环 执行一段命令_cmd装比代码无限循环-程序员宅基地
文章浏览阅读10w+次,点赞14次,收藏18次。代码如下:for /l %a in (0,0,1) do echo hello,world粘贴在cmd命令行窗口中,回车即可无限死循环输出hello,world。如果需要停止,可以按ctrl+c中断。解析通用形式:for /l %variable IN (start,step,end) DO command [command-parameters] 该集表示以增量形式从start到end的一个数字序列。具体到第一段代码,如果是 (0,0,1) 就是从0开始,每次增_cmd装比代码无限循环
随便推点
uni-app,uni-table表格操作_uniapp table-程序员宅基地
文章浏览阅读8.5k次,点赞2次,收藏11次。使用uni-ui UI框架实现表格加分页功能,uni-table 和uni-pagination 组件的使用示例加完整代码。_uniapp table
HTML5本地存储账号密码
【代码】HTML5本地存储账号密码。
vue.js知识点-transition的钩子函数应用(实例展示)_transition 钩子-程序员宅基地
文章浏览阅读1.6k次。本小结通过transition的钩子函数实现小球半场动画头条-静敏的编程秘诀-vue教程合集知识点1:入场、出厂方法beforeEnter表示动画入场之前,此时,动画尚未开始,可以在beforeEnter中设置元素开始动画之前的起始样式enter表示动画开始之后的样式,这里可是设置小球完成动画之后的,结束状态enter(el,done)el:动画钩子函数的第一个参数:el,..._transition 钩子
MyBatis 多表映射及动态语句
主要梳理mybatis多表及动态使用
Qt 多线程基础及线程使用方式-程序员宅基地
文章浏览阅读2.9w次,点赞98次,收藏777次。文章目录Qt 多线程操作2.线程类QThread3.多线程使用:方式一4.多线程使用:方式二5.Qt 线程池的使用Qt 多线程操作应用程序在某些情况下需要处理比较复杂的逻辑, 如果只有一个线程去处理,就会导致窗口卡顿,无法处理用户的相关操作。这种情况下就需要使用多线程,其中一个线程处理窗口事件,其他线程进行逻辑运算,多个线程各司其职,不仅可以提高用户体验还可以提升程序的执行效率。Qt中使用多线程需要注意:Qt的默认线程为窗口线程(主线程):负责窗口事件处理或窗口控件数据的更新;子线程负责后台的业_qt 多线程
GQA分组注意力机制
【代码】GQA分组注意力机制。